
この記事は、2025/9/11に公開された「Unlocking Enterprise AI Potential: Knowledge Distillation for Customer Support Analytics」の翻訳です。
現代の企業は大きな課題に直面しています。競争力を維持するために高度な AI モデルを活用したい一方で、クラウドベースの大規模言語モデル (LLM) にかかる高コストを抑え、データプライバシー規制への準拠を維持する必要があるのです。
では、企業はどのようにすれば、予算を超過させたり機密データをさらしたりすることなく、最先端の AI を活用できるのでしょうか。Cloudera では、この課題をチャンスへと変えるソリューションを開発しました。プライベートデータから生成された合成データとナレッジ・ディスティレーションを活用することで、コスト効率に優れ、正確かつコンプライアンスに準拠した AI システムを構築できるのです。
本記事では、Cloudera AI Studios の一部である Cloudera Synthetic Data Generation Studio が、実データが不足している場合や機密性の高い場合でも、組織が AI のイノベーションを活用できるようにする方法について解説します。
ユースケースと重要なポイント
ユースケース:社内のユースケースを基に、プライベートデータから生成された合成データを用いた知識蒸留によって、Cloudera のカスタマーサポートチケットパイプラインのパフォーマンスと全体的なスループットを大幅に向上させた方法を、データのプライバシーと規制コンプライアンスを維持しつつ紹介します。
主要なポイント:
競争優位としてのデータプライバシー:合成データにより、規制リスクを伴わずにイノベーションを実現。
コスト効率の高いパフォーマンス:小規模で微調整されたモデルが、大規模でリソースを多く消費する代替手段を上回る性能を発揮。
複数のユースケースに適用可能:同じアプローチを、不正検知からパーソナライズされたカスタマーサービスまで幅広いユースケースに活用可能。
ビジネス上の課題:データプライバシーを損なうことなく AI モデルの速度と精度を両立
Cloudera のカスタマーサポートチームは、AI モデルを活用してサポートチケットをリアルタイムで分析・要約しています。このシステムは、顧客や Cloudera サポート担当者のコメントを入力として受け取り、それぞれのコメントを分析し、感情分析や要約といった一連の分析結果を抽出します。これらの分析は、Cloudera におけるカスタマーエクスペリエンスを向上させる上で極めて重要です。
このパイプラインで処理される顧客データは機密性が高いため、ローカル環境で稼働するモデルのみを使用でき、顧客データを外部ソースと共有することは一切できません。
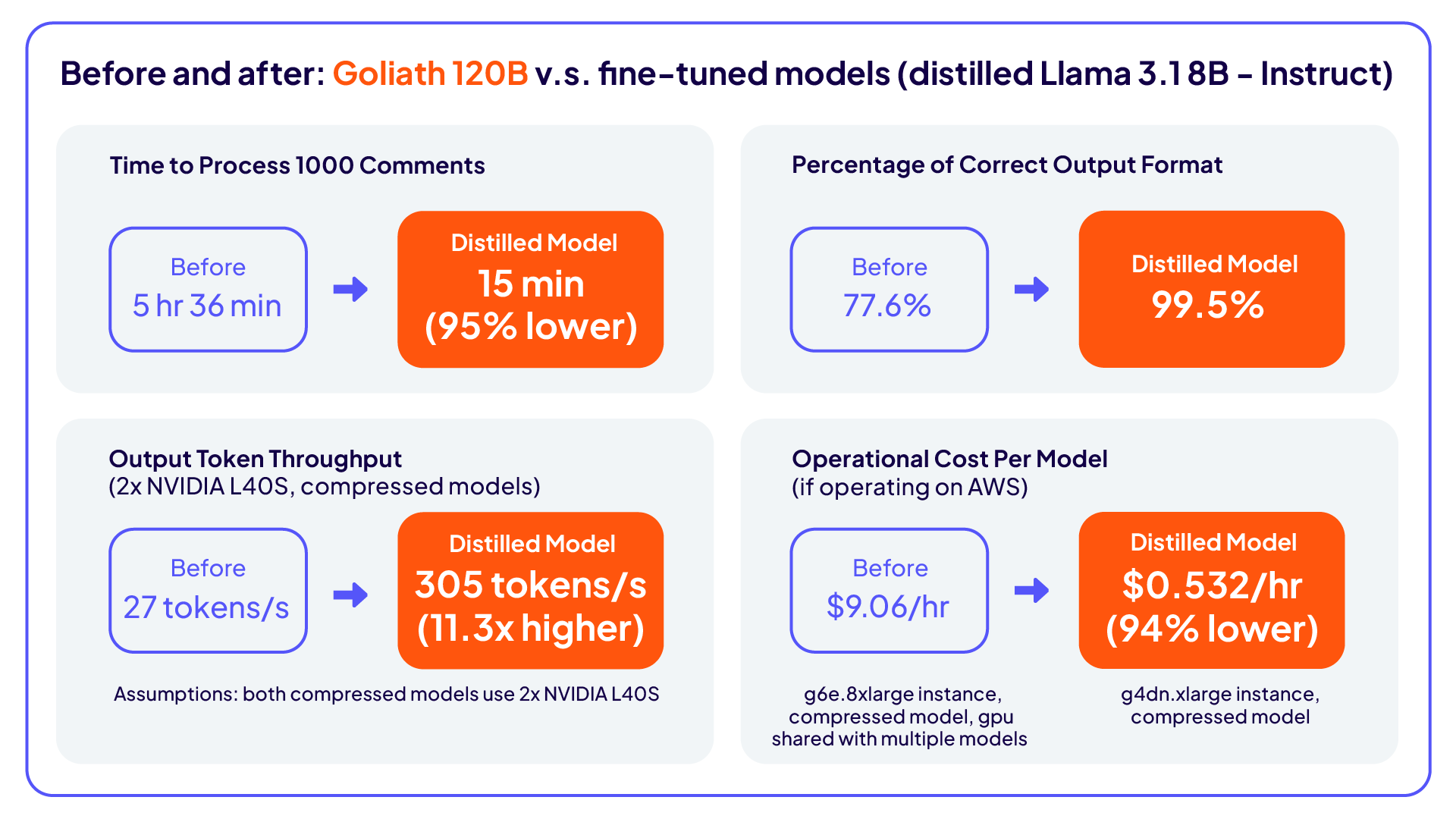
当初、コメントを分析するためにチームはローカルの LLM (Goliath 120B) に依存していました。これにより基本的な性能要件は満たされましたが、速度と生成性能に課題がありました。平均で 1 件あたりの処理に12~15秒を要し、30秒ごとにリクエストが発生していたのです。期待される出力への適合率は77.5%にとどまり、生成精度も独自モデルより低く、スケーラビリティや LLM の性能におけるボトルネックとなっていました。
ローカルの大規模 LLM (Goliath-120B) を使用する際の課題は明白でした。応答時間の遅さ、コストの増大、最新のクラウドベースモデルと比べた生成精度の低さ、そしてコンプライアンスリスクです。
大規模組織も同様のトレードオフに直面しており、AI の精度と速度をデータ漏洩リスクと天秤にかけてバランスを取らなければなりません。
Cloudera のソリューション:プライベートデータを活用したナレッジ・ディスティレーション
Cloudera のブレークスルーは、プライバシーを最優先としたナレッジ・ディスティレーションのアプローチにあります。
規制や漏洩リスクを伴う生の顧客データでモデルをトレーニングする代わりに、Cloudera Synthetic Data Studio を用いて合成データセットを生成しました。Cloudera AI に新たに搭載されたこのローコードツールは、技術的な質問やトラブルシューティングシナリオなど、実際のやり取りを模倣しつつ、一切の機密情報をさらすことなくデータを作成します。
合成のカスタマーサポートインタラクションを生成することは、規制面や情報漏洩リスクにおける利点をもたらしただけでなく、チームがその合成データを最新のクラウドベース LLM に送信し、顧客感情などのインサイトを最高性能の LLM から抽出することも可能にしました。これらのクラウドベース LLM は、大規模なローカル LLM よりもはるかに正確な情報処理を実現し、最先端の LLM から正確なインサイトを抽出するための理想的な情報源となりました。
Cloudera の合成データソリューションは、コンプライアンスやプライバシーのリスクを排除し、既存の大規模ローカル LLM を上回る最高品質の合成データを生成しました。このアプローチにより、最先端モデルから小規模 LLM へ知識を抽出する選択肢が開かれ、Goliath-120B と同じ課題を、より低コストかつ高精度で解決できるようになりました。
プロセス
データ生成:Synthetic Data Studio のデータ生成ワークフローを用いて、Claude Sonnet に顧客からの質問と回答を生成するよう指示するプロンプトを作成しました。このプロンプトは、LLM にカスタマーサポートの質問と回答を作成させ、トーンを設定し、構造を詳細に規定するよう指示しています。さらに、実際のデータに現れるトピック (Cloudera AI や Cloudera Data Warehouse のカスタマーサポートなど) のリストを提示し、シードトピックを活用することで、多様かつ現実的なカスタマーサポートチケットを生成できるようにしました。
ファインチューニング:フィルタリングしたデータのみを使用し、チームはデータを学習用と開発用に分割して、Claude Sonnet モデルから Meta Llama3.1-8B-instruct モデルへ知識を抽出しました。チームは、最適化された LLM の性能を最大化するファインチューニングのパラメータを選択するために、複数の実験を行いました。
評価:Synthetic Data Studio の評価ワークフローを用いて、チームは LLM-as-a-judge に生成データの品質を評価させ、低品質なサンプルを除外するためのプロンプトを作成しました。
人間による評価と自動化された LLM-as-a-judge 評価の両方を活用し、チームは実際のカスタマーサポートチケットの質問と回答を採点しました。Cloudera のチームは、デプロイ済み LLM と抽出された LLM の回答に違いが出たケースに注目し、それぞれの LLM の勝率を報告しました。さらに、平均実行時間、期待される出力への適合率、モデルのデプロイコストといった観点から、速度の改善度も測定しました。
結果
速度の向上:処理時間が95%短縮されました。
出力構造の改善:出力の適合率が77.5%から99.5%に上昇しました。
LLM 精度の向上:小規模なナレッジ・ディスティレーションを経た LLM (Llama 3.1 8B) とデプロイ済み Goliath LLM (Goliath 120B) を比較したところ、Phi-4 を評価者とした場合の勝率は 70%対 30%、人間による評価では 63%対 37%となりました。
コストと効率の改善:小規模なナレッジディスティレーションを経た LLM は、コンピュートとメモリの要件を削減しながらリアルタイムでのスケーラビリティを高め、データプライバシーを維持しました。その結果、スループットは 11 倍に向上しました。
結果は明らかです。企業はデータプライバシーを損なうことなく、AI 活用の卓越性を実現できます。学習データを合成し知識を抽出することで、企業はイノベーションとコンプライアンスの間でトレードオフを迫られることを回避できます。
規制リスクなくイノベーションを実現する合成データ
ナレッジ・ディスティレーション手法を開発することで、Cloudera は処理時間を 95%削減し、出力構造の適合率を 99.5%に高めました。さらに、Phi-4 を評価者とした場合に 70%、人間による評価で 63%の精度で従来の Goliath 120B モデルを上回る Llama 3.1 8B モデルを導入しました。
この方法は、機密データを直接使用しないことでコンプライアンスリスクを排除し、スループットを11倍に向上させました。これにより、小型で微調整されたモデルが、速度と精度の両方で、大規模でリソースを多く消費する代替モデルを上回ることが示されました。
AMP をお試しいただき、カスタマーサポートのユースケースにおいて、大規模モデルから小規模モデルへ合成プライベートデータを用いて知識を抽出する方法をご確認ください。



