Cloudera Data Warehouse
スピード、コスト、セキュリティを損なうことなく、何千もの同時ユーザー向けに膨大なデータを管理および分析できます。

概要
あらゆる場所のあらゆるデータを実際に役立つビジネスの洞察に簡単に変換。
あらゆるサイズとタイプのデータに対して、他社のデータウェアハウスを上回る性能を発揮し、コスト効率に優れた拡張性を実現する、クラウドネイティブのセルフサービス型の分析環境です。
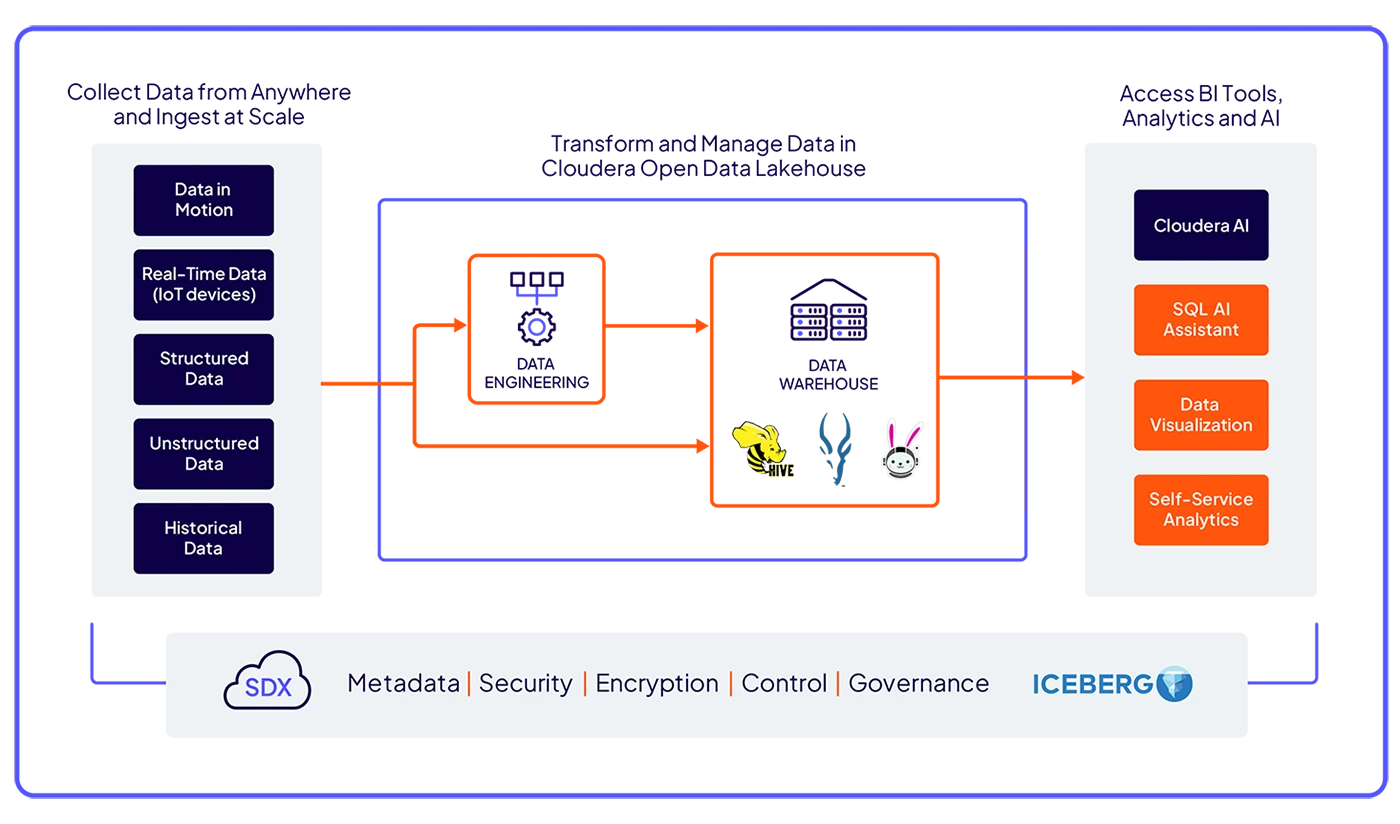
高度な SQL エンジンによる高速クエリ、インテリジェントな自動化、AI を活用した SQL、および最適化されたワークロードパフォーマンスで、強力な洞察を引き出します。
Apache Iceberg を活用した統合プラットフォーム上で分析ワークフローを安全かつ確実に構築し、あらゆる場所でシームレスなデータアクセスを実現します。
クラウドネイティブなオープンソースのエンジンを通じてワークロードの柔軟性を確保し、データを完全に統制しながら、ベンダーロックインを回避します。
ユースケース
ワークロードに最適なエンジンを選び、低コストで運用
-
フェデレーションクエリとアドホック探索による深い洞察
単一の SQL クエリでさまざまなシステムのデータを分析できます。
-
意思決定支援とビジネスインテリジェンスの強化
あらゆる場所のあらゆるデータにセルフサービスでアクセスできるようにし、重要な洞察を迅速に提供します。
-
ETL パイプラインとバッチ処理によるデータ品質の向上
構造化データと非構造化データを柔軟かつ高速に分析できるようにします。
-
Apache Iceberg を活用した多機能分析
下流の分析作業やレポート作成に向けて、大量の構造化データを変換および準備します。
-
フェデレーションクエリとアドホック探索による深い洞察
単一の SQL クエリでさまざまなシステムのデータを分析できます。
-
意思決定支援とビジネスインテリジェンスの強化
あらゆる場所のあらゆるデータにセルフサービスでアクセスできるようにし、重要な洞察を迅速に提供します。
-
ETL パイプラインとバッチ処理によるデータ品質の向上
構造化データと非構造化データを柔軟かつ高速に分析できるようにします。
-
Apache Iceberg を活用した多機能分析
下流の分析作業やレポート作成に向けて、大量の構造化データを変換および準備します。
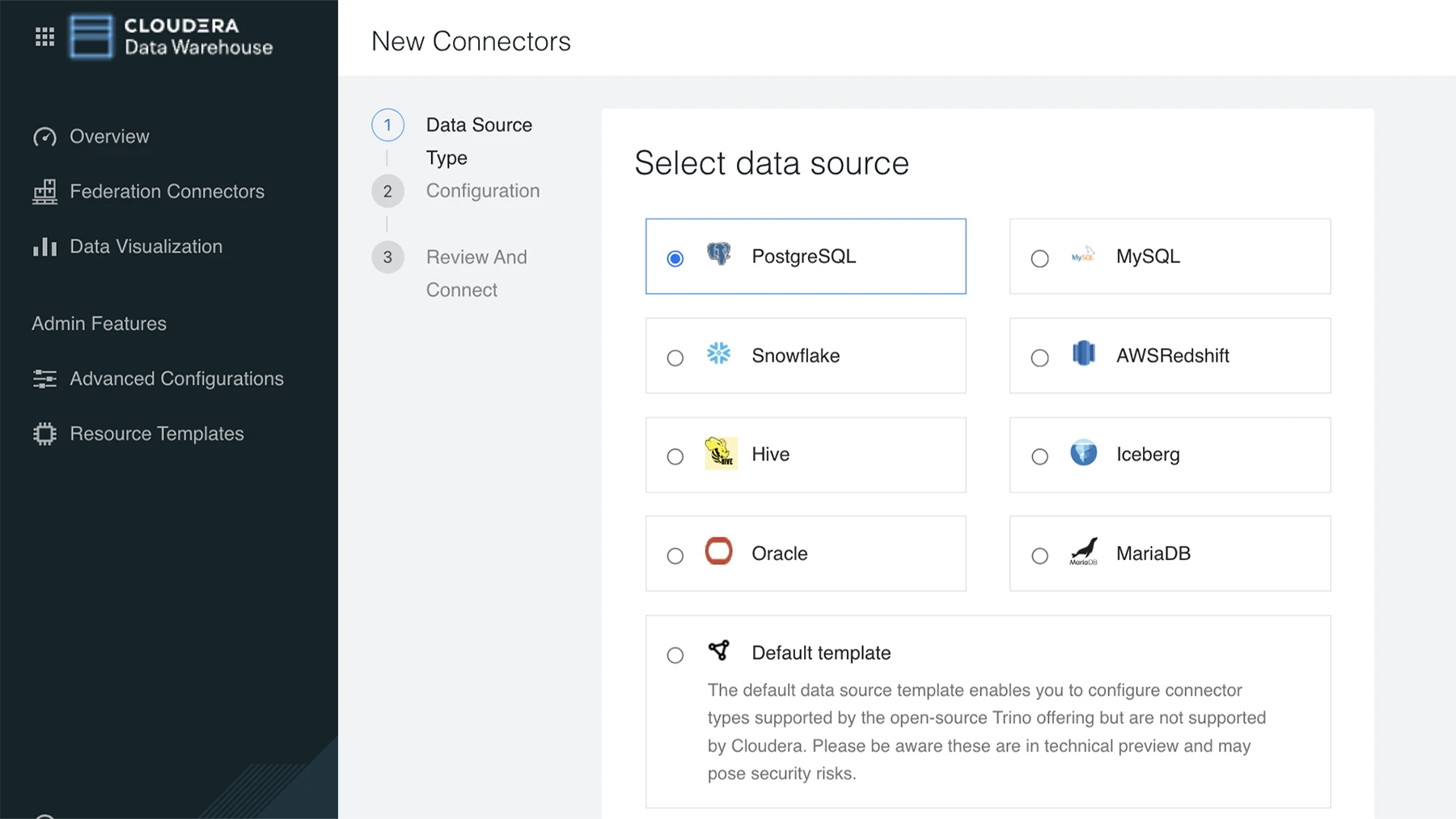
データアナリストやデータサイエンティストが、さまざまなソースにまたがる膨大な分析データセットに対してクエリを実行できます。
データの移行や複雑な統合を行うことなく、さまざまなソースのデータを分析できます。

イベントデータや時系列データに対する低レイテンシのセルフサービスアクセスを可能にします。
リアルタイムデータを大規模に活用し、迅速なクエリの実行を可能にするインタラクティブなレポートやダッシュボードを構築できます。
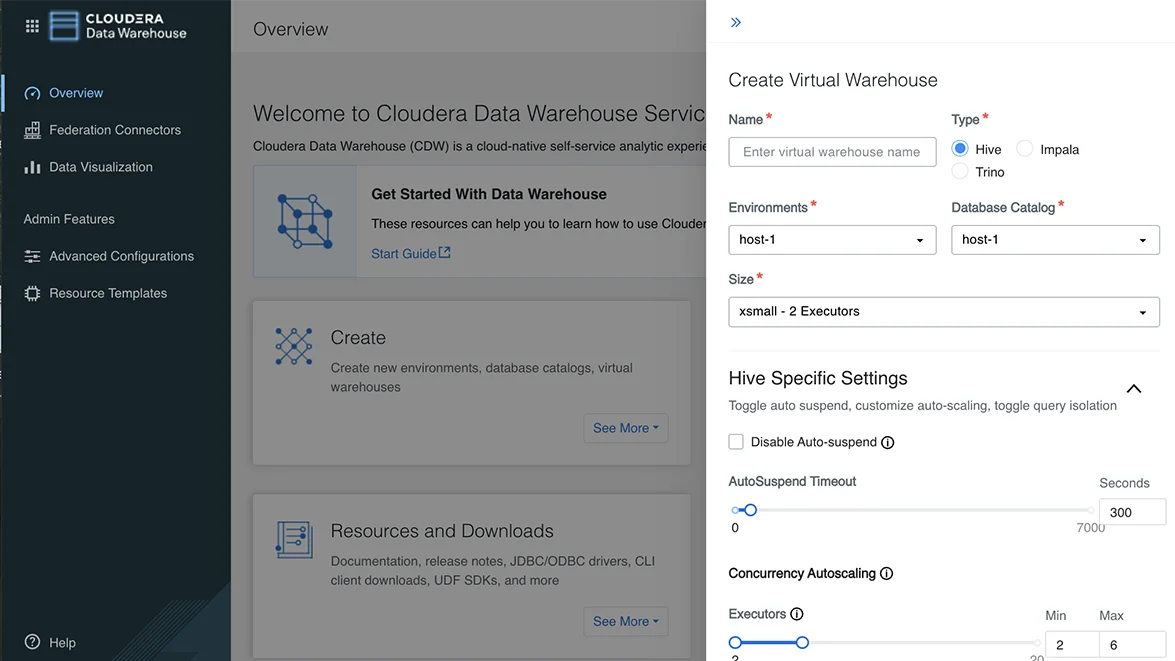
大規模なデータセットや大量のスケジュール済みジョブに対して複雑なクエリを実行します。
下流の分析作業やレポート作成に向けた大量の構造化データの変換や準備をサポートします。

好みのツールを使ってデータ分析できるようにします。
サードパーティー製エンジンとのシームレスな相互運用を実現し、組織全体でデータを統合してコラボレーションを強化します。
Cloudera Data Warehouse の主な特長
ドメインの専門家および SQL ガイドとして機能します。ユーザーが自然言語でデータのニーズを入力すると、アシスタントが関連するデータを見つけ、クエリを作成し、最適化して、わかりやすい言葉で説明します。
Cloudera Data Visualization を通じて、AI を BI 機能に組み込み、シームレスですぐに使える可視化機能を提供します。インタラクティブなダッシュボードを構築し、社内で速やかに洞察を共有できます。
単一の仮想ウェアハウスでさまざまなワークロードを最大限の効率で実行します。このアプローチにより最適なコストパフォーマンスが実現するため、費用を抑えてスムーズかつ効率的にデータ操作を行うことが可能となります。
構造化データと非構造化データを含む、さまざまなワークロードとデータタイプをサポートします。この汎用性は、高度な分析、ダッシュボードでのレポート作成、リアルタイム処理など、あらゆるワークロード要件に適用できます。
統合された組み込みのセキュリティとガバナンスで、オンプレミス環境とクラウド環境を統合します。ハイブリッド機能、データアクセス、ポータビリティ、および拡張性により、さまざまなフォームファクタ間でデータの安全な読み書きを実現します。
顧客
Cloudera Data Warehouse とともに成長し、イノベーションを実現するお客様
Cloudera への投資によって、データを最大限に活用できるようになり、イノベーションと効率性を推進するとともに、卓越したカスタマーエクスペリエンスを提供する能力を大幅に高めることができました。



Apache® Iceberg への移行 - 初心者向けガイド
Apache Iceberg へのワークロード移行に関するステップバイステップのガイドをお読みください。

{kind=link}
その他の製品を見る
Apache Spark で Iceberg テーブルを処理することで、エンタープライズグレードのデータパイプラインを安全に構築、オーケストレーション、管理できます。
AI を活用したダッシュボードを通じて、ビジネスユーザーがガバナンスの効いたデータを迅速かつ簡単に探索し、共同で作業して洞察を獲得できるようにします。