Cloudera Unified Data Fabric
組織内のデータサイロを解消し、分散したデータソースをインテリジェントかつ安全に接続することによって、組織のすべてのデータを把握できる統合ビューを提供します。

概要
どこからでもデータにアクセスして、あらゆる場面で AI を活用
断片化されたデータ管理から脱却しましょう。エージェント型 AI を活用すれば、クラウド、データセンター、エッジにまたがるすべてのデータを、信頼できる価値ある洞察に変えることができます。
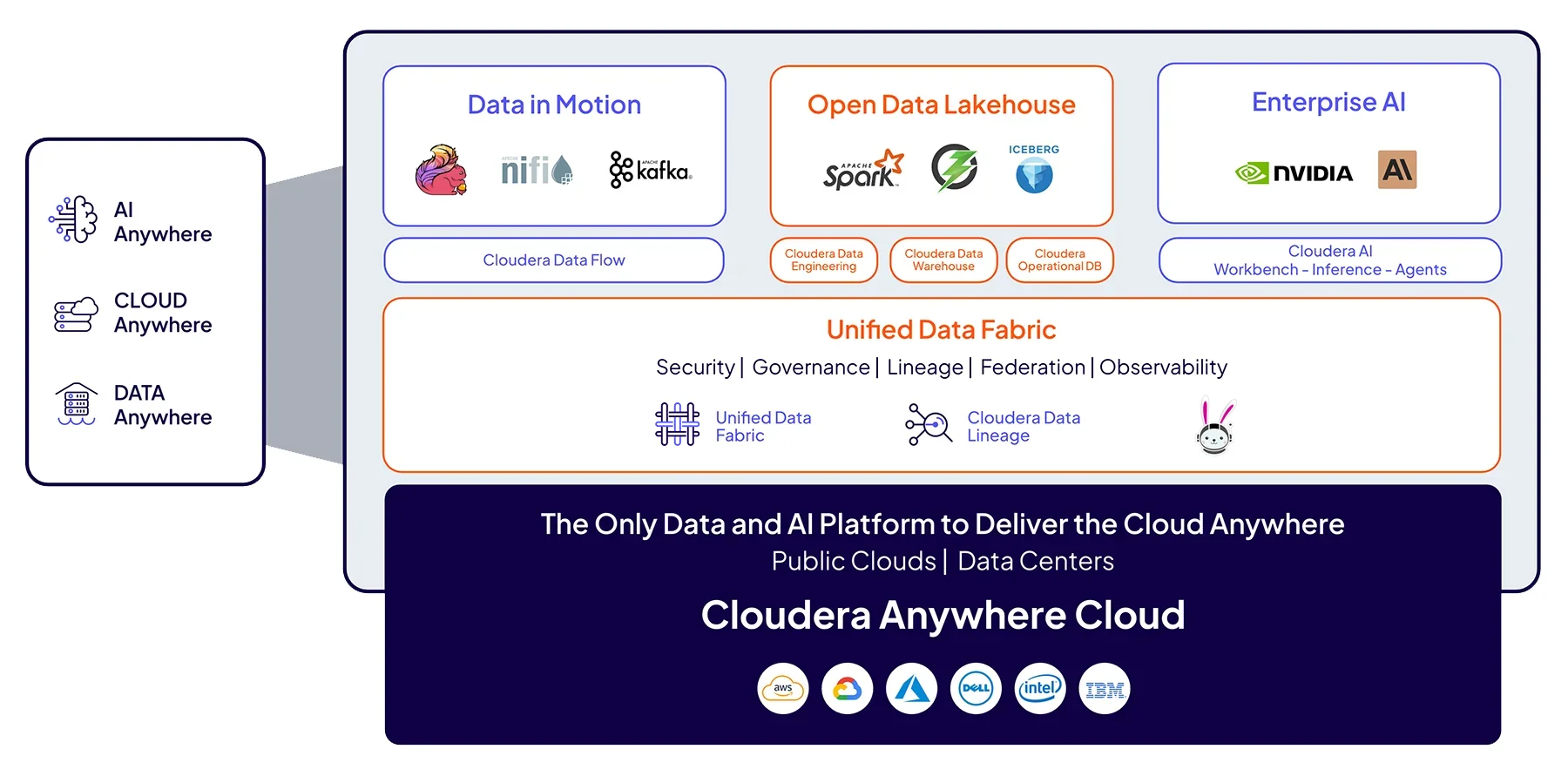
メタデータを有効化し、データガバナンスとセキュリティを自動化することによって、すべてのデータに対する検索とアクセスを可能にします。
エンドツーエンドのインテリジェントなデータリネージにより、拡張性と信頼性に優れた信用できる統合データを提供します。
データを一切移動させることなく、さまざまなシステムを使用しているチーム間のコラボレーションとデータ共有を改善します。
ユースケース
すべてのデータを接続して AI ドリブンな洞察に変換
AI を活用した自動化やエージェント型アプリケーションに対応したガードレールを設けながら、データ資産全体を可視化し、どこでどのように洞察を適用すべきかを判断します。

Cloudera Agent Studio が、本番環境に対応したエージェントワークフローのライフサイクル全体での管理をサポートします。
データ分類、タグ付け、ラベル付けを実行するエージェントを構築し、確信を持ってデータを活用し、洞察を生み出せるようになります。

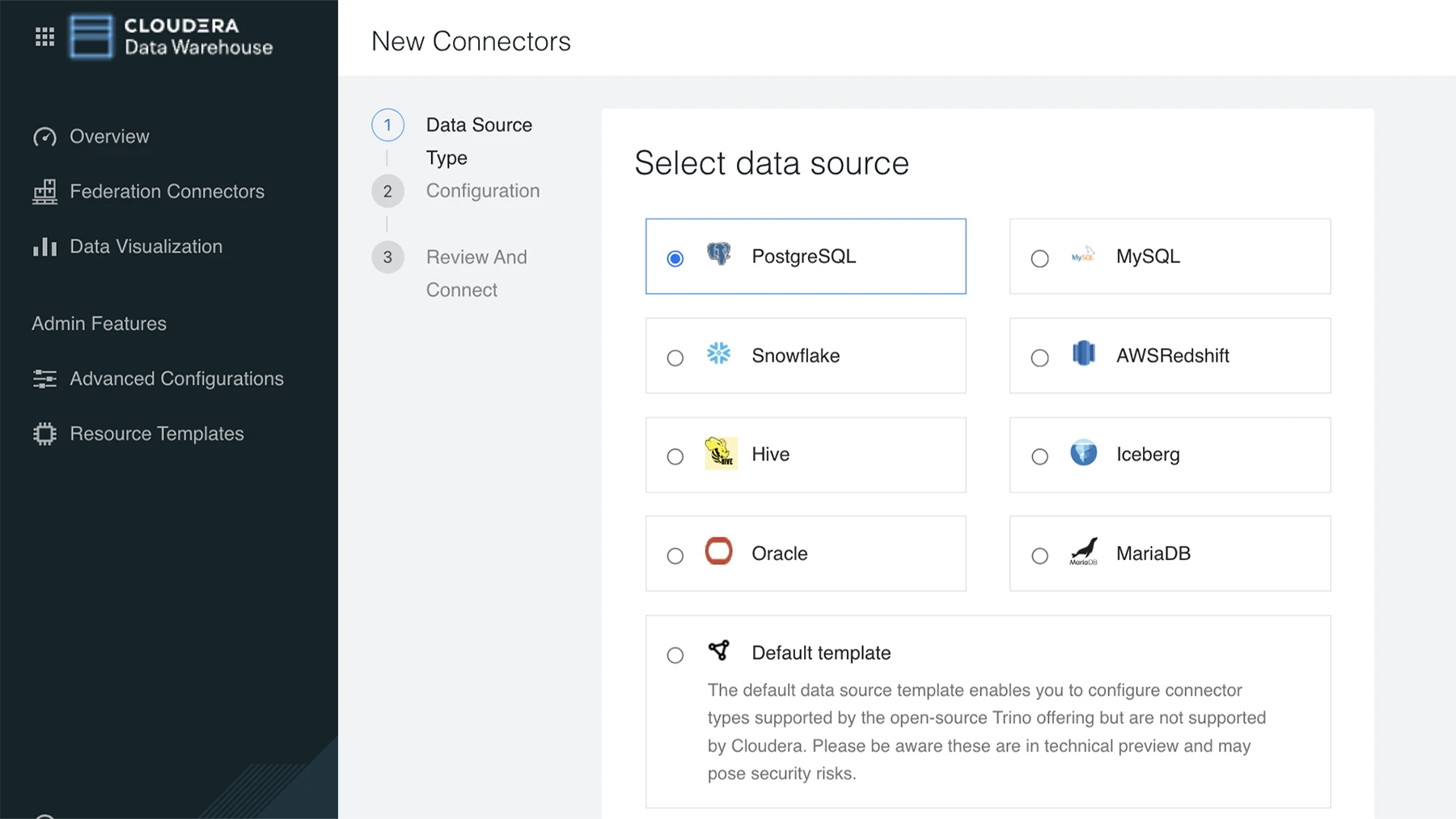
多様なデータソースとデータタイプを、単一の統合データプラットフォームに統合します。
信頼性が高い接続済みの統合データを使用して、リアルタイム RAG パイプラインを強化し、モデリングデータの準備を加速します。
データを統合して、複数のソースにまたがってクエリを包括的に把握できるようにし、安全なデータ共有を実現します。
Trino と Cloudera Data Warehouse が、フェデレーションアクセスと統合ガバナンスを実現し、データ資産を検索可能なナレッジグラフにマッピングします。
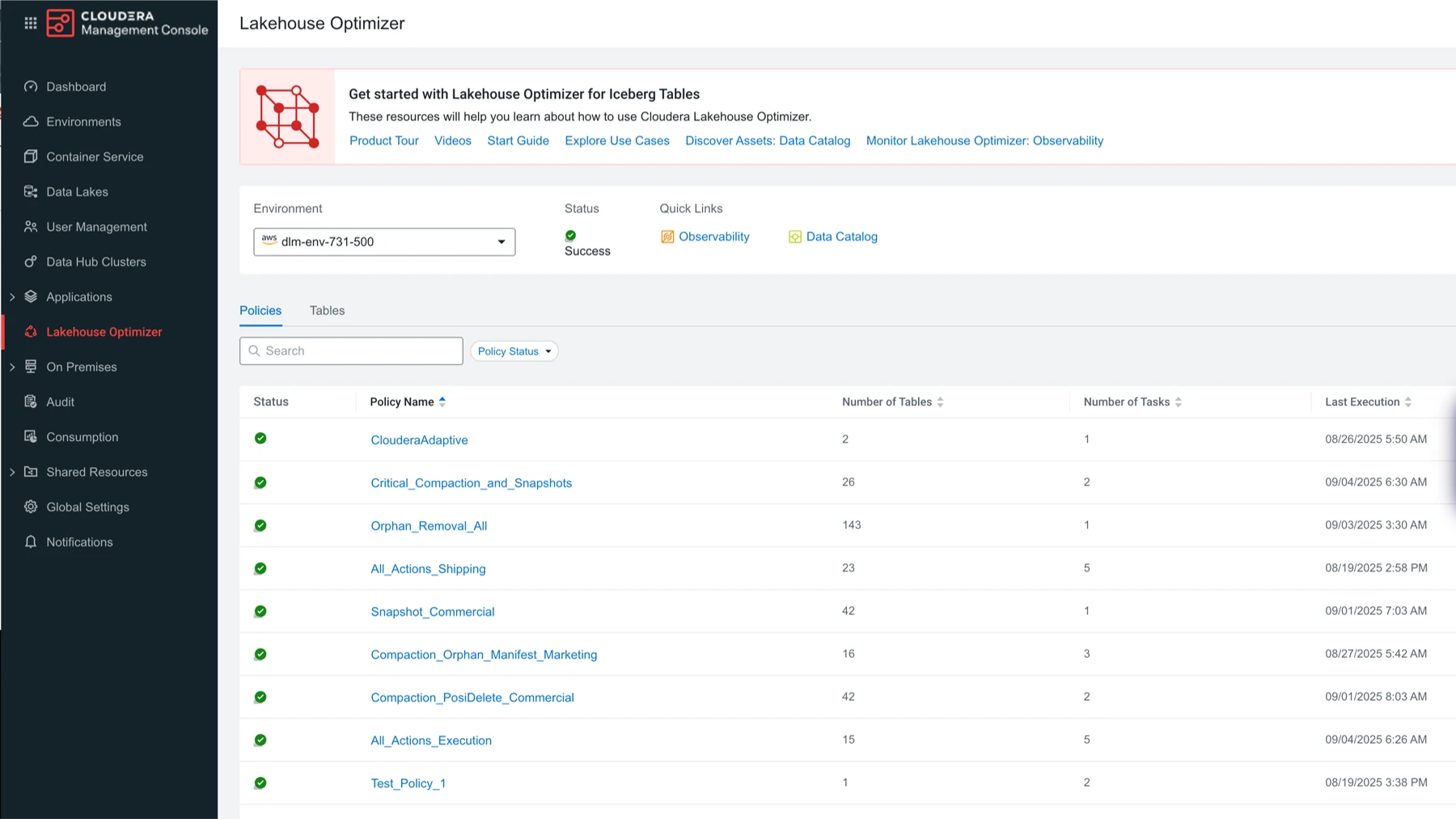
ローコードツールやノーコードツールを使用して、一元化され、ガバナンスの効いたメタデータレイヤを介して共有データ製品を構築します。
Cloudera の Iceberg REST カタログが、統合されたガバナンスを維持しながら、各種サードパーティーエンジン間で安全かつコピー不要なデータ共有と相互運用性を実現します。
単一の SQL クエリでさまざまなシステムのデータにアクセスできます。Cloudera Data Warehouse の Apache Trino は、オブジェクトストレージ、レイクハウス、主要なリレーショナルデータベース、および新しいストリーミングシステムや NoSQL システム全体のクエリを統合します。
変革、依存性、関係性を分析することによってシステム間のデータフローを自動でマッピングし、Cloudera Data Lineage を活用して複合セマンティックレイヤを作成し、これを可視化します。
Cloudera Data Catalog で直感的な検索、充実したメタデータ、コンテキストに応じた洞察をユーザーに提供してデータを迅速に検出し、信頼できるようにします。60以上のコネクターを使用して、メタデータ、スクリプト、コード、依存関係を迅速に収集します。
Cloudera Data Lakehouse は ETL、データコピー、データ移動を一切行うことなく、異なるシステム間のコラボレーションとデータ共有を改善し、AI ワークフローに向けたデータ永続化とデータ処理の基盤を提供します。
あらゆるソースのデータに接続して、どこへでも配信できます。Cloudera のデータ・イン・モーションが、リアルタイムのデータの採取、処理、分析を行い、使いやすい可視化ツールとノーコードツールを提供します。
Cloudera Shared Data Experience (SDX) がセキュリティ、ガバナンス、メタデータを統合し、一貫したポリシーの適用、コンプライアンスの確保、および信頼性の高いデータアクセスをあらゆる場所で実現します。


次のステップへ
Cloudera Unified Data Fabric でデータの大規模な準備、統合、管理を確実に行う方法をご紹介します。
Cloudera SDX のドキュメント
Cloudera SDX がデータ・ファブリックの柱として情報のセキュリティを確保する仕組みについて、詳細をご覧ください。
Cloudera Data Lineage のドキュメンテーション
Cloudera Data Lineage がメタデータを収集し、データ資産全体をエンドツーエンドでマッピングする仕組みについて、詳細をご覧ください。