Cloudera Data Flow
ユニバーサルデータ配信、俊敏性、スケールを制限なく実現します。

効果的なデータ配信で AI と分析を加速
Cloudera Data Flow は、Apache NiFi を搭載したクラウドネイティブのデータサービスで、データ移動のエンドツーエンドプロセスを効率化して、ユニバーサルデータ配信を促進します。
データソースに依存しない450以上のコネクターで、複数のデータセンターとクラウドにわたって、あらゆるデータをあらゆるソースからあらゆる場所にシームレスに移動します。
シンプルなアーキテクチャーで効率を最大限に高め、データのロックインを回避しながら、ツールの急増を抑制し、データ移動の重複を減らします。
データパイプラインのライフサイクルのあらゆるフェーズで、ノーコード開発者にセルフサービスを提供することで、次のレベルの俊敏性を実現します。
Apache NiFi 2.0をサポートする唯一のベンダーである Cloudera
オンプレミス
パブリッククラウド
独自の持ち込み (BYO) クラスタ環境における Kubernetes のオペレーターとして対応
ユースケース
ビジネスクリティカルなデータを最大限の効率でリアルタイムに提供
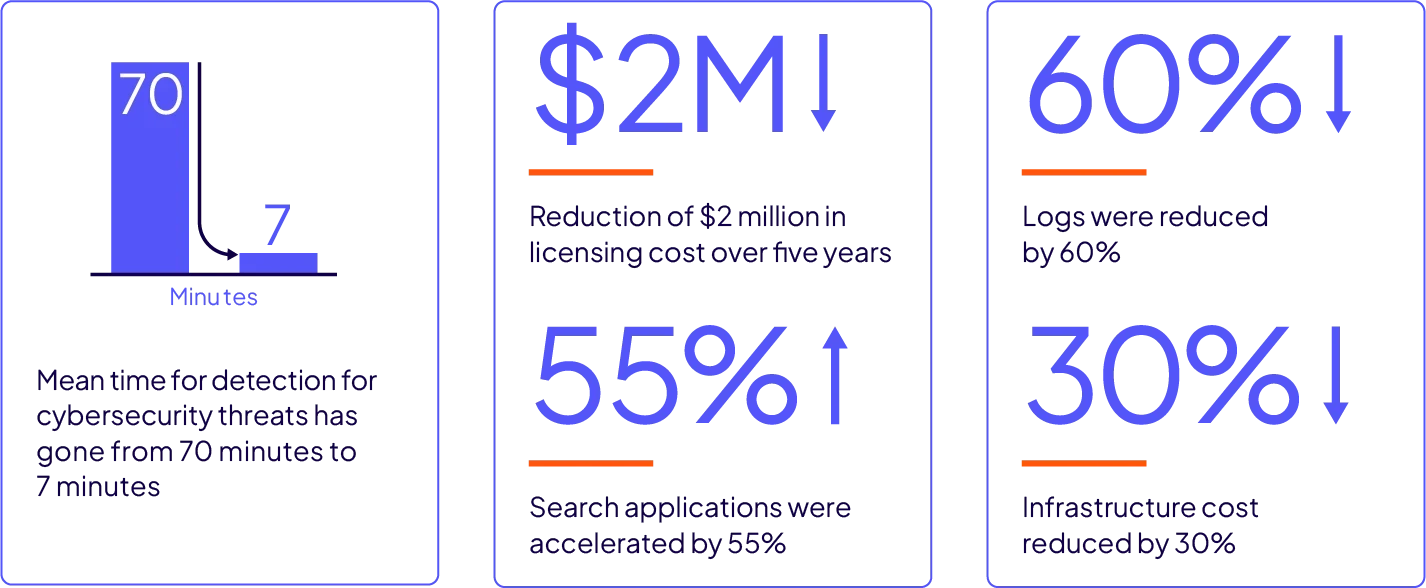
データが発生した瞬間に処理と分析を実行し、異常、サイバー攻撃、不正行為を防止します。
エッジからクラウドまで、データを即座にアクションにつなげ、被害が発生する前に阻止します。

AI エージェントを最新のマルチモーダルデータで強化し、リアルタイムの文脈をプロンプトに追加します。
推論を実行したりアクションを自動化したりする AI エージェントに最新の文脈とデータを提供します。
継続的な可視化によって意思決定を迅速化し、業務の信頼性を向上させます。
ビジネスオペレーション全体で重要なイベントを即座に検出し、把握して対応します。
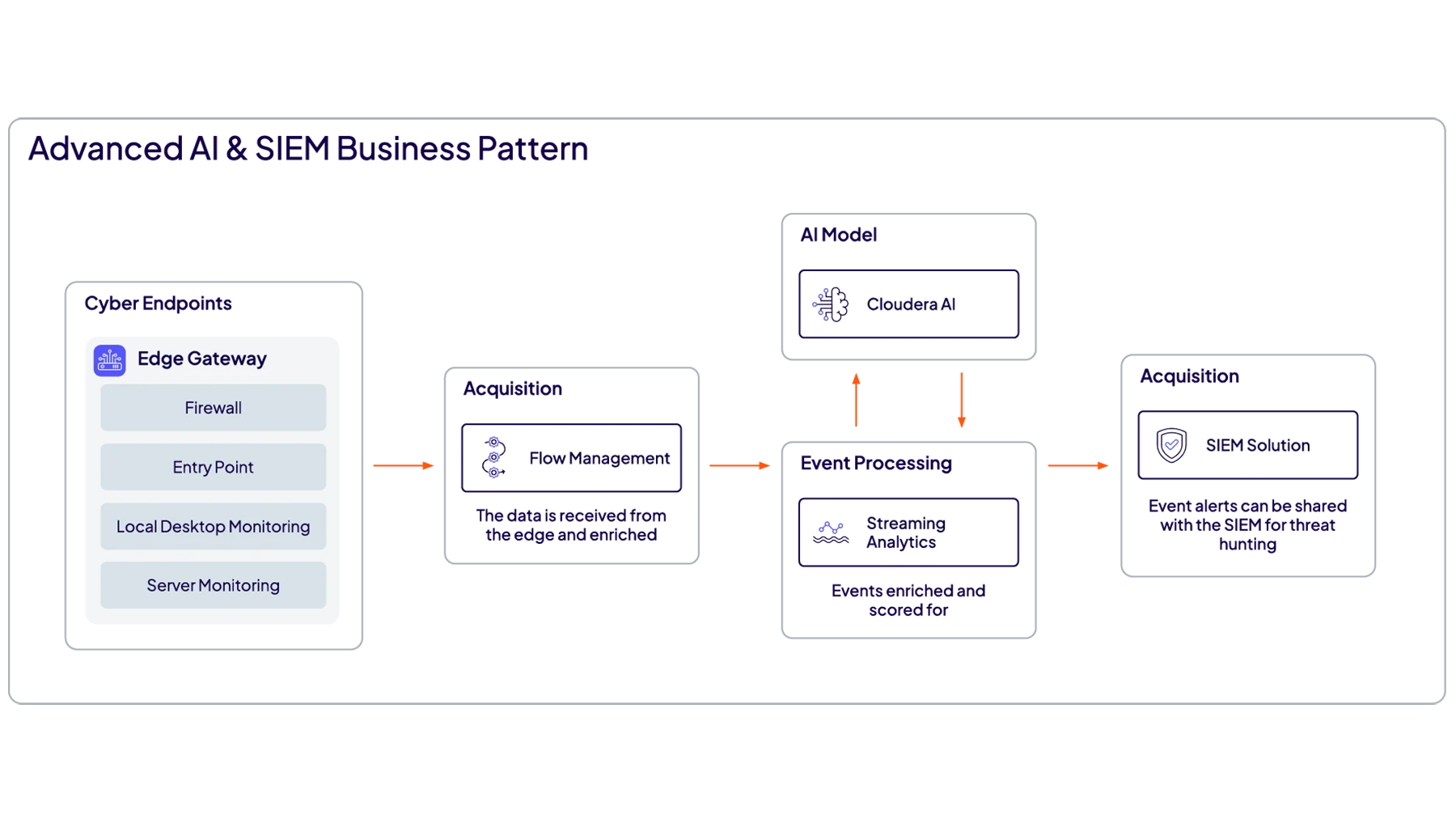
あらゆるシステムやデバイスからあらゆるタイプのデータを収集して処理し、そのデータを分析可能な状態にして、あらゆるユーザーやシステムにリアルタイムで提供します。
「一度作成すればあらゆる場所にデプロイできる」ため、共通のデータフローをすばやく展開して、短期間でビジネス成果を達成できます。進化するビジネスニーズとデータニーズに対応するため、バージョン管理を簡素化します。
サーバーレスでコストが最適化された、拡張性の高い運用を実現します。AWS Lambda、Azure Functions、Google Cloud Functions によるイベントドリブンなユースケースとリアルタイムのファイル処理をサポートします。HTTPS リクエストによってトリガーされるマイクロサービスを、コーディング不要の直感的な UI から構築できます。
すべての NiFi フローデプロイメントの監視を単一のダッシュボードに集約します。フローデプロイメント用の KPI アラートを設定し、重要なパフォーマンス指標を追跡します。動的なスケーリングでパフォーマンスを維持し、効率的に SLA を達成します。
包括的なコネクティビティ
業界標準のプロトコルを活用し、データストリーム、データベース、データレイク、エンタープライズアプリケーションなどの専用コネクターを介して、オンプレミスまたはあらゆるクラウドのあらゆるシステムに接続できます。
主要なコネクター
Apache Iceberg
データレイクとデータウェアハウス
Apache Kafka
データストリーム
Delta Lake
データレイクとデータウェアハウス
Google BigQuery
データレイクとデータウェアハウス
MongoDB
データベース
Salesforce
エンタープライズアプリケーション
Snowflake
データレイクとデータウェアハウス

Milvus
生成 AI
導入オプション
柔軟なデプロイオプションで、あらゆるデータと場所に対応
クラウドの Cloudera
クラウドの Cloudera で Data Flow をデプロイすると、弾力性を高めながらシンプルな管理を実現できます。
オンプレミスの Cloudera
Cloudera Flow Management で NiFi フローをデプロイすると、レイテンシを最小限に抑えながらデータとリソースを最大限に統制できます。
Kubernetes のオペレーターとして
Cloudera Flow Management Operator for Kubernetes を単独でデプロイすると、最短で価値を実現できます。




{kind=link}
その他の製品を見る
あらゆる場所の構造化データと非構造化データをリアルタイムで取り込み、処理し、分析することで、即時に洞察を獲得し、アクションを実行し、AI 活用を強化できます。