
この記事は、2025/11/21に公開された「The Future Delivered Today: The AI-Powered Data Lakehouse」の翻訳です。
Cloudera のオープンな基盤なら、データがどこにあっても100%アクセス可能
業界全体にわたり、データチームは、データをインテリジェンスに変換する方法を探っており、情報を保存する以上の機能を備えたシステムの構築および実行方法がないか再検討しています。また、これらのシステムが相互運用できることも重要です。AI モデル、機能パイプライン、ビジネスインテリジェンス(BI)レポート、およびバッチジョブは、多くの場合、複数のチームとエンジンにまたがります。現在では、コピーやリファクタリングを行わずに境界を越えてデータを共有することが最優先事項となっています。
組織はこれまで、BI やレポート用に最適化されたデータウェアハウスと、大規模な AI および機械学習(ML)用に設計されたデータレイクから成る2層のアーキテクチャに依存してきました。しかし、この2つが分離されていることにより、複雑なデータ移動、専門的なエンジニアリング、ほとんど同期されないシステム間での重複したストレージといった問題があり、コストがかかっていました。
Cloudera のオープンレイクハウスアーキテクチャは分析(BI、アドホッククエリ)と AI(予測および生成 AI、または GenAI)のワークロードを一元的に管理されたデータ基盤に統合することで、この課題に対処します。組織は、この一元化されたデータアーキテクチャにより、Apache Iceberg などのオープンテーブル形式を使用して、(データを計算に持ち込むのではなく)計算をデータに持ち込むことができ、データの近くで AI ワークロードを実行するための基盤が提供されます。レイクハウス上の AI ワークロードはガバナンスされ、バージョン管理された、高品質のデータを直接操作できます。
Cloudera は、あらゆる場所のデータに AI の力をもたらす唯一のデータ AI プラットフォーム企業であり、実績のあるオープンソースの基盤を活用して、パブリッククラウド、データセンター、エッジを統合する一貫したクラウドエクスペリエンスを提供します。
AI ワークロードの実行におけるオープンな基盤の重要性
企業はここ10年で、長期的な成功を収めるにはパフォーマンスとスケーラビリティだけでは不十分であり、柔軟性と相互運用性が不可欠であることを学びました。AI ワークロードの活用においては特に、独自の形式やシステムに制約されることなく、さまざまなデータソース、フレームワーク、ツールを使用できる能力が必要です。
そこで、Apache Iceberg などのオープンテーブル形式がデータプラットフォームのアーキテクチャを変えました。Iceberg は、テーブルの論理的定義を物理的なストレージレイアウトから切り離し、複数のエンジンとフレームワークが完全なトランザクション保証の下で同じデータを読み書きできるようにします。このオープン性により、パイプラインを書き換えることなくインフラストラクチャを進化させ、新しいコンピューティングエンジンを採用することが可能になります。
本番環境レベルのパイプラインを実行するには、AI ライフサイクルのすべての段階でデータ、モデル、およびガバナンスをつなぐことができる統合プラットフォームが必要です。ここで中核となるのは、未加工のデータ、構造化データ、半構造化データ、および非構造化データを継続的に AI 対応の形式へと変換し、モデルのトレーニングおよび評価の系統管理と再現性を維持するデータおよび特徴量エンジニアリングパイプラインです。
生成 AI では、従来の ML の枠を超えた、新たな運用要件が導入されます。チームは固有のタスクを解決するために、検索拡張生成(RAG)向けのインフラストラクチャとデータへのアクセスを取得し、プライベートデータでの大規模言語モデル(LLM)を微調整し、エージェント型ワークフローを構築して、モデル、プロンプト、モデルコンテキストプロトコル(MCP)(API)を組み合わせる必要があります。これらのワークロードは、表形式のデータと非構造化データ(テキスト、ドキュメント、画像、埋め込み)の両方に依存しており、どれも単一のデータおよびメタデータプレーンで管理されます。また、これらのモデルを安全かつ効率的に展開して提供するには、スケーラブルな推論層が不可欠です。
AI ワークロードの多機能化とエージェント化が進むにつれて、カタログやメタデータへのアクセスの重要性も増していきます。AI パイプライン、検索システム、自律エージェントはすべて、データセットの検出、トレーニング状態の再現、系統管理の維持にメタデータを活用しています。オープンカタログは、データセットがどこでどのように処理されるかに関係なく、これらのシステムがデータセットを照会、登録、追跡するための普遍的な方法を提供します。
Cloudera のオープンな基盤により、組織は分析、予測、生成 AI のワークロードを完全にサポートできます。
Cloudera の統合データと AI プラットフォーム
Cloudera のオープンデータレイクハウスは、Apache Iceberg や REST カタログなどのオープンな基盤を活用し、データエンジニアリング、分析、AI をガバナンスの効いた同一のアーキテクチャ上に統合します。このプラットフォームは、すでにデータが存在する場所でワークロード(分析ワークロードまたは AI ワークロード)が動作する必要があるという原則に基づいて設計されています。データの移動や複製の摩擦を排除することで、チームはデータの取り込み、変換、分析、モデル運用にまたがる継続的なパイプラインを、完全な系統と統制を備えた状態で構築できます。
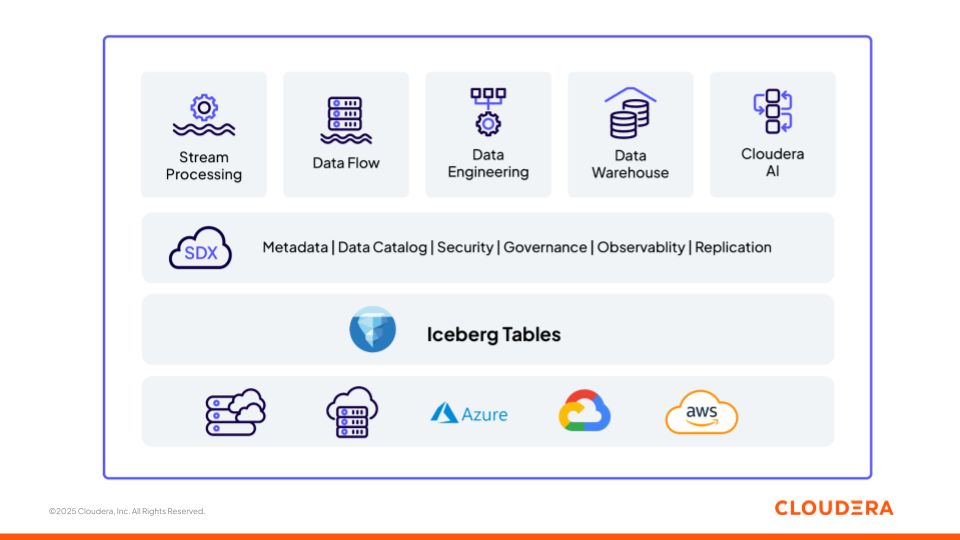
図1:オープンな基盤(Apache Iceberg)上に構築された Cloudera のデータと AI プラットフォーム
ここからは、Cloudera のプラットフォーム(図1)に含まれるさまざまなコンポーネントが、ML パイプラインや 生成 AI アプリケーションを構築するチームをどのようにサポートするのか、またデータと AI のライフサイクルのさまざまな段階(取り込みから推論まで)にどのように対応するのかを、相互運用可能な単一のプラットフォームとして動作させながら確認します。各コンポーネントはオープンスタンダードに基づいて構築されており、環境間での柔軟性と相互運用性を保証します。
ストレージ: Apache Iceberg
Apache Iceberg は、Cloudera のレイクハウスアーキテクチャを支える、オープンでバージョン管理されたトランザクションテーブルフォーマットです。Iceberg は、スキーマの進化、タイムトラベル、アトミック操作を可能にし、分析ワークロードと AI ワークロードの両方を同じ管理されたデータ上で一貫して操作できるようにします。Cloudera は、安全に管理され、いつでも過去の履歴に遡れる基盤を提供し、一貫性があり追跡可能なデータビューからすべてのモデル、プロンプト、検索タスクが取得されるようにします。
スキーマの進化などの Iceberg のネイティブ機能も、AI データセットの進化と密接に連携しています。特徴量ストア、トレーニングデータセット、検索コーパスはすべて Cloudera のレイクハウス内で同じ Iceberg テーブルを共有でき、スナップショットを使用してトレーニングデータの一貫性を保持しながら、新たな推論用データの流れを維持できます。これにより、分析テーブルと AI 固有のストレージの間の境界がなくなります。
取り込み:Cloudera データ・イン・モーション
Cloudera DataFlow は Apache NiFi 上に構築されており、レイクハウスへの継続的なデータ移動の基盤となります。これにより、データベース、API、IoT デバイス、イベントログなど、さまざまなエンタープライズソースからの低レイテンシの取り込みが可能になり、バッチとストリーミングの両方のワークロードをサポートします。NiFi のネイティブ Apache Iceberg 統合における最近のイノベーションにより、中間ステージングなしでオープンレイクハウスにデータを直接書き込むことができるようになりました。NiFi と Iceberg のこの緊密な連携により、パイプラインの複雑さが軽減され、データの取り込みと同時にオープンテーブル形式でデータを書き込めるようになります。
リアルタイムのユースケースでは、NiFi、Apache Kafka、Apache Flink がイベントドリブン型の取り込みファブリックを形成します。NiFi はデータのオーケストレーションとルーティングを行い、Kafka は永続的なストリーミングを提供し、Flink はデータを Iceberg に永続化する前にリアルタイムのエンリッチメントを可能にします。この設計により、下流のすべての消費者にわたってデータが最新の状態に保たれ、管理された状態が維持されます。この連続したマルチモーダルデータの流れこそが、レイクハウスの AI ワークロードを支えています。リアルタイムデータを一貫したガバナンスの下、Iceberg テーブルで継続的に利用できるようにすることで、企業は生成 AI システムにドメイン固有の情報をタイムリーに提供し、RAG パイプラインとエージェントのワークフローをより正確で、根拠のある、信頼性の高いものにすることができます。
カタログ:Cloudera Iceberg REST カタログ
Cloudera Iceberg REST カタログ(オープンな REST 仕様に基づく)は、オープン仕様をサポートするサードパーティエンジン(Snowflake、Redshift、Databricksなど)が Iceberg テーブルにゼロコピーアクセスできるようにする中央集権型かつ相互運用可能なメタデータサービスを提供します。1つのプラットフォームで提供される1つの計算エンジンに制限されることなく、タスクに最適なコンピューティングを柔軟に選択できるため、この側面は組織にとって非常に重要です。Cloudera が提供するセキュリティおよびガバナンスポリシーがあらゆる場所のデータに適用され、環境間の一貫性が保証される一方で、ユーザーは好みのツールを使用できます。
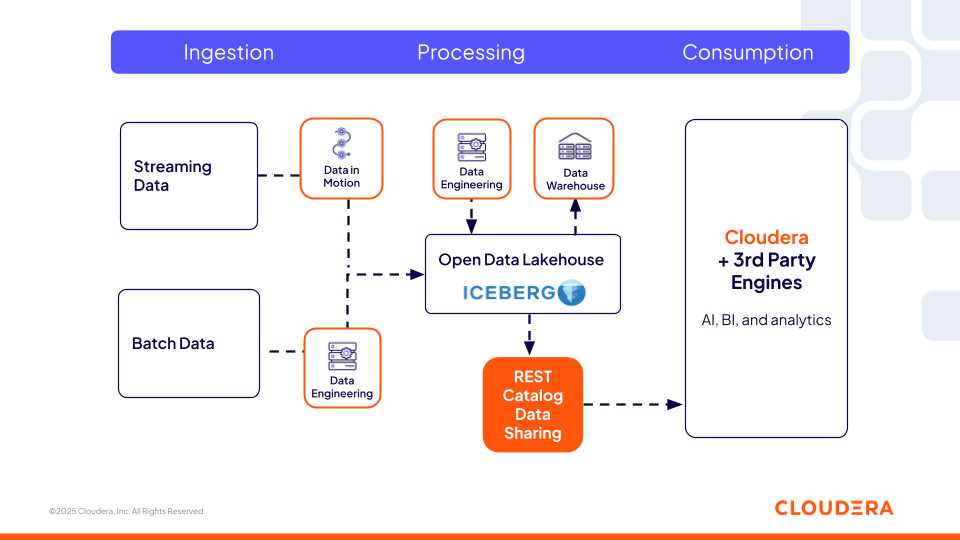
図2:Cloudera の Iceberg REST カタログでサードパーティエンジンとの相互運用性を実現
このカタログレイヤーは、機能エンジニアリングパイプライン、エージェント型ワークフロー、および検索システムが、管理されたデータセットを動的に検索してアクセスする上で重要です。AI エージェントは、企業データのナレッジグラフと同じように、REST カタログを使用して Iceberg テーブルをクエリできます。また、利用可能なテーブルを検出し、そのスキーマを解釈し、パーティショニング、スナップショット、リネージなどのテーブルメタデータを考慮して、使用するデータセットを決定できます。
セキュリティとガバナンス:Cloudera SDX
Cloudera Shared Data Experience(SDX)は、取り込みから推論に至るまで、あらゆるサービスにまたがる統一されたセキュリティおよびガバナンスのフレームワークです。SDX は、データのリネージ、監査、アクセス制御、ポリシー適用のための単一の一貫したレイヤーを提供し、すべてのワークロードが実行場所に関係なく同じセキュリティモデルを継承できるようにします。また、エンタープライズ ID システム(LDAP、SSO、OAuth)と統合し、構造化データと非構造化データにわたって、役割ベースおよび属性ベースのきめ細かなアクセス制御をサポートします。
Cloudera は、SDX をオープンなレイクハウス基盤と組み合わせることで、データ、モデル、AI エージェントが同じ管理境界内で動作することを保証し、分析ワークロードと生成 AI ワークロードの両方に透明性、再現性、信頼性を提供します。
Cloudera のデータサービスと AI サービス
統合サービスレイヤーは、チームが AI を変換、分析、および運用化するために必要なすべての機能を統合し、管理された同一のデータ上で同時に作業することを可能にします。
Data Engineering
Cloudera Data Engineering は、オープンソースの Apache Spark と Apache Airflow を基盤に構築れており、Iceberg テーブル上でデータパイプラインの構築、オーケストレーション、スケーリングを行うサーバーレスサービスを提供します。これにより、ハイブリッド環境間での分析や AI ワークロードに対する信頼性が高く、再現可能な ETL および機能パイプラインを実現します。
AIサービス
Cloudera AI サービスレイヤーは、モデルのトレーニングや微調整から安全な導入まで、AI のライフサイクル全体の運用化を Iceberg と同じ管理されたデータ基盤上でネイティブに実行します。また、モデル開発、登録、推論を、データエンジニアリングと AI の運用をつなぐ単一のワークフローに統合します。
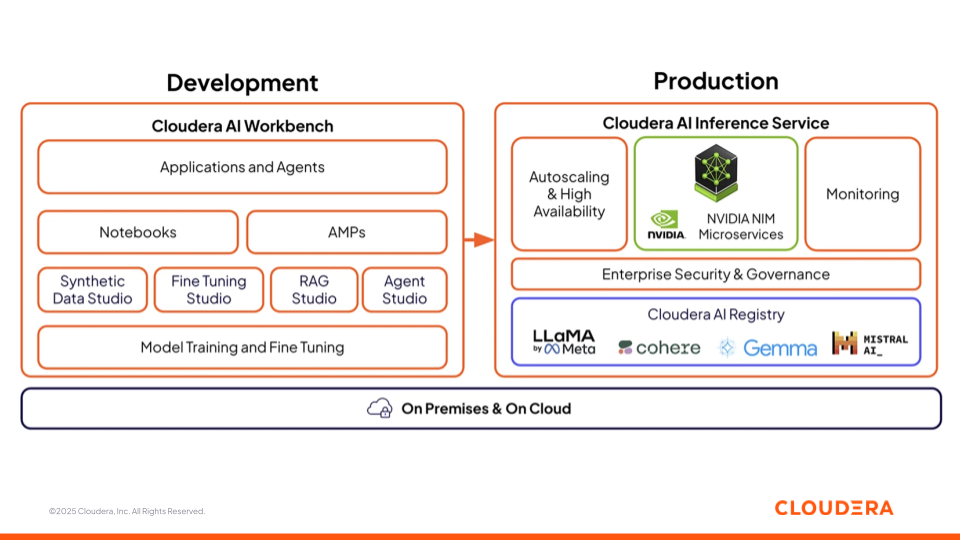
図3:Cloudera AI の AI Workbench および AI Inference サービス
Cloudera AI Workbench
Cloudera AI Workbench は、データサイエンティスト、アナリスト、エンジニアがモデルを開発、微調整、テストするためのコラボレーション環境です。この環境ではノートブック、ローコードのアプリケーションビルダー(AMP)、および AI 開発のあらゆる段階に対応する専用スタジオを統合しています。Cloudera AI Workbench は AI の開発と展開を加速するため、ビジネスチームと技術チームのギャップを埋め、AI プロジェクトにおけるコラボレーションを促進する以下の4つの AI スタジオを支えています。
- Synthetic Data Studio は、実際のデータが限られている場合や制限されている場合に、テストやモデルのトレーニング用の合成データセットを生成します。
- Fine-Tuning Studio は、オープンファンデーションモデルを企業固有のデータセットに適合させ、関連性と精度を高めます。
- RAG Studio は、LLM(OpenAI、Anthropic、Amazon Bedrock など)を関連するプライベートデータに接続し、根拠のあるコンテキスト出力を実現する RAG パイプラインを構築します。
- Agent Studio では、モデル、MCP、API、内部データソースを使用して、ドメイン固有のタスクを自動化する、マルチステップのエージェント型ワークフローを作成できます。
これらの機能はすべてオープンなレイクハウス(Iceberg の基盤上)で動作し、安全な管理下での、特定のタスクに必要なデータへのゼロコピーアクセスをチームに提供します。
Cloudera MCP サーバー
Cloudera は、オープンソースのCloudera AI Workbench MCP サーバー をはじめとする一連の新しい MCP サービスを通じて、AI プラットフォームのオープン性を拡大しています。このサービスは AI システムの統合用に設計されており、AI ワークベンチ内でエージェント機能とツール呼び出し機能を有効にします。また、LLM が Cloudera AI Workbench の機能やコンポーネントと安全にやり取りするためのフレームワークを提供し、モデル、データ、アプリケーションを自動化されたエンタープライズワークフローに取り込みます。知的エージェントはこのアーキテクチャにおいて、規制の厳しい業界で必要とされるセキュリティ、制御、監査機能を維持しながら、信頼できる管理された Cloudera 環境全体でタスクの推論、実行、自動化を行うことができます。
Cloudera AI Inference サービス
Cloudera AI Inference Service は、自動拡張、高可用性、エンドツーエンドの観測可能性を備えたモデルを本番環境に導入します。従来の ML モデルと大規模言語モデル(LLM)の両方をサポートし、予測と応答を低遅延で提供します。モデルは、エンタープライズグレードのセキュリティを備えた REST または gRPC エンドポイントとして展開でき、アプリケーションやエージェントからの信頼性が高く一貫したアクセスを保証します。
推論層に統合された Cloudera AI Registry は、追跡、バージョン管理、成果物の保存、系統化のための MLflow 互換 API を備えた集中型モデルライフサイクル管理を提供します。Llama、Cohere、Gemma、Mistral など、さまざまなオープン言語モデルやエンタープライズ言語モデルのオプションから選択できます。
推論層には組み込みの監視機能と可観測性も含まれており、チームは SDX ガバナンスを通じて完全な系統とコンプライアンスを維持しながら、レイテンシー、スループット、モデルのドリフトを追跡できます。これにより、エンタープライズグレードの AI の重要な要件であるモデル予測が説明可能で追跡可能になります。
未来は AI によって推進され、AI はあらゆるデータによって駆動される
AI の成功は、モデルやエージェントの能力だけでなく、データアーキテクチャにも大きく依存しています。レイクハウスは、分析、運用、AI のワークロードを単一の管理されたデータプレーンに統合する基盤を提供します。オープンスタンダードに基づいて構築されていれば、データ、メタデータ、モデルをツール、クラウド、チーム間で問題なく相互運用できます。
Cloudera AI Workbench、AI Inference Service、統合 AI レジストリが一体となって、オープンレイクハウス基盤の上でデータから AI へのライフサイクルを完成させます。管理された Iceberg テーブルとオープンメタデータアクセスに基づいて直接構築されたこのスタックにより、すべてのモデル、プロンプト、エージェントが信頼できるバージョン管理されたデータ上で動作することが保証されます。
エンタープライズ AI の未来は、独自のスタックによって定義されるのではなく、共有された標準と透明な相互運用性を通じてデータ、ガバナンス、インテリジェンスを統一するオープンな基盤によって定義されるでしょう。
Cloudera でデータを安全に大規模に準備、統合、分析する方法について詳しくは、製品デモをご覧ください。または 5 日間の無料トライアルにご登録ください。
