
この記事は、2024/1/26に公開された「Metadata Management and Data Governance with Cloudera SDX」の翻訳です。
本ブログ記事では、Cloudera プラットフォームのデータ・ガバナンス・フレームワークにきめ細かいアクセス制御を実装するプロセスについて、順を追ってご説明します。これにより、データオフィスはタグや分類、ビジネス用語集、データ・カタログ・エンティティのようなメタデータ管理資産に対するアクセスポリシーを実装し、包括的なデータアクセス制御の基礎を築くことができます。
優れたデータガバナンス戦略では、ユーザーが戦略的データ資産にアクセスできるレベルをビジネスが制限できるようにする役割を定義することが重要です。従来、データ・ガバナンス・オフィスは主に3つの役割を担っています:
- データスチュワード:企業ガイダンスとデータガバナンス要件に従って、データ利用のビジネスルールを定義する
- データキュレーター:データ利用者がデータ資産を検索できるように、データスチュワードが定義したルールに従ってデータ分類を割り当て、実行する
- データコンシューマー:データ資産から洞察と価値を引き出し、データに適用されるタグと用語の品質と一貫性を意欲的に理解しようとする
Cloudera プラットフォーム内では、オンプレミスまたは主要なパブリック・クラウド・プロバイダーのいずれかを使用して展開されているかにかかわらず、Cloudera Shared Data Experience (SDX) がデータセキュリティとガバナンス全般の一貫性を保証します。SDXはあらゆる展開の基本的な部分であり、データ管理機能を提供するために2つの主要なオープン・ソース・プロジェクトに依拠しています。Apache Atlas は拡張可能かつ伸張可能なコア・ガバナンス・サービスのセットを提供し、Apache Ranger はデータとメタデータ両方の包括的なセキュリティを有効化、監視、管理します。
この記事では、Apache Atlas に格納されたメタデータ管理資産に対してセキュリティポリシーを作成し、Apache Ranger を使用してきめ細かいアクセス制御戦略を実装する方法をご説明します。
事例紹介
この記事では、企業のセントラル・データ・リポジトリ内でメタデータオブジェクトへのアクセスを制御したいデータ・ガバナンス・オフィスを例にご説明します。これにより、組織は政府の規制や社内のセキュリティポリシーに準拠することができます。このタスクのために、データ・ガバナンス・チームはまず財務ビジネスユニットに注目し、組織内のさまざまなタイプのユーザーの役割と責任を定義しました。
この例では、3種類の異なるユーザーが存在し、これにより Cloudera プラットフォームでデータガバナンス戦略を実装するために、Apache Ranger ポリシーを通じてApache Atlasオブジェクトに割り当てることができるさまざまなレベルの権限を示すことができます。
- adminはデータ・ガバナンス・オフィスのデータスチュワード
- etl_userは財務チームのデータキュレーター
- joe_analystは財務チームのデータコンシューマー
必要であれば、追加の役割やアクセスレベルを作成するのも同様に容易なことにご留意ください。例に沿って進めていくとわかりますが、Apache Atlas と Apache Ranger が提供するフレームワークは、非常に柔軟でカスタマイズが可能です。
まず、データスチュワードによって一連の初期メタデータオブジェクトが作成されます。これにより、財務チームは、日々の業務の一環として関連資産を検索できるようになります。
- “PII”、”SENSITIVE”、”EXPIRES_ON”、”DATA QUALITY”などの分類(または”tags”)
- 3つの主要ビジネスユニット用に作成された用語集および用語: “Finance”、”Insurance”、”Automotive”
- “Project”と呼ばれるビジネス・メタデータ・コレクション
注:ビジネスメタデータの属性の作成は、こちらの手順に従ってください。
次に、財務ビジネスユニットに関連するデータ資産へのアクセスを制御するために、以下の条件で一連のポリシーを実装する必要があります。
財務データキュレーター<etl_user>に許可されるのは以下のみです:
- “finance”という単語で始まる作成/読み取り分類
- “finance”という単語で始まるタグで分類されたエンティティや、”worldwidebank”プロジェクトに関連するエンティティの読み取り/更新。ユーザーは、これらのエンティティにラベルやビジネスメタデータを追加することもできる
- 以前の仕様によるエンティティの分類の追加/更新/削除
- “finance”に関連する用語集および用語集の用語の作成/読み取り/更新
財務データコンシューマー<joe_analyst>に許可されるのは、以下のみです:
- 資産を検索するための “finance” に関連する分類の閲覧とアクセス
- “finance”に関連するタグで分類されたエンティティの閲覧とアクセス
- “finance”用語集の閲覧とアクセス
次のセクションでは、これらのポリシーを実装するプロセスについて詳しくご説明します。
細かなアクセス制御の実装(ステップ・バイ・ステップ)
上述のビジネスニーズを満たすために、Apache Ranger のアクセスポリシーをどのように設定し、Apache Atlas のメタデータ資産を保護・制御するかを実証します。この目的のため、パブリックAMIイメージを使用して、すべての SDX コンポーネントを含む Cloudera データプラットフォーム環境をセットアップしました。環境のセットアッププロセスは、こちらの記事でご説明しています。
1.分類タイプの認証
分類はApache Atlas のコアの一部です。これは、組織がビジネスプロセスを推進するデータ資産への理解を助け、整理し、共有するために提供されるメカニズムの1つです。重要なのは、データ資産間の系統関係に従って、エンティティ間で分類を ”propagate” できることです。propagationの詳細については、こちらのページをご参照ください。
1.1データスチュワード - admin user
分類へのアクセスを制御するには、データスチュワードの役割を担うadmin userが以下の手順を実行する必要があります。
- Rangerコンソールにアクセスする
- Atlasリポジトリにアクセスし、ポリシーを作成・管理する
- 財務ビジネスユニットのデータキュレーターとデータコンシューマーに適切なポリシーを作成する
まず、Rangerのadmin UIからAtlas Rangerポリシーリポジトリにアクセスします。
 画像 1 - Rangerメインページ
画像 1 - Rangerメインページ
Atlasポリシーリポジトリ内:
 画像2 - Atlasポリシー
画像2 - Atlasポリシー
最初に表示されるのは、デフォルトのAtlasポリシーです(注釈1)。Apache Rangerではアクセスポリシーを “allow”ルールと”deny”ルールの両方で指定することができます。しかし、”principle of least privilege”を適用することは、あらゆるセキュリティーコンテキストにおいて推奨されるグッドプラクティスです。すなわち、デフォルトでアクセスをdenyし、選択的にのみアクセスをallowします。これは、すべての人にアクセスをallowし、選択的にアクセスをdenyしたり除外したりするよりも、はるかに安全なアプローチです。したがって、最初のステップとして、デフォルトのポリシーが、この例のシナリオにおいて、制限しようとしているユーザーに包括的なアクセスを許可していないことを確認する必要があります。
その後、新しいポリシーを作成できます (例: denyポリシーを作成することで、デフォルトポリシーのパブリックアクセスを削除します。注釈2)。最後に、新しく作成したポリシーがセクションの下部に表示されることが確認できます(注釈3)。
“Add New Policy”ボタンをクリックした後:
 画像3 - 財務分類に関するポリシーの作成
画像3 - 財務分類に関するポリシーの作成
- まず、ポリシー名と、必要に応じてポリシーラベルを定義します(注釈 1)。これらはポリシーに”functional”な影響を与えませんが、時間の経過とともに環境が拡張しても、セキュリティポリシーを管理しやすくするための重要な要素です。ポリシーの命名規則を採用するのが一般的で、これには、ポリシーが適用されるユーザーグループおよび/または資産の手短な説明、およびその意図の表示が含まれる場合があります。この例では、ポリシー名を”FINANCE Consumer - Classifications”とし、”Finance”、”Data Governance”、”Data Curator”というラベルを使用します。
- 次に、ポリシーを適用するオブジェクトのタイプを定義します。この例では、”type-category”を選択し、”Classifications”と入力します(注釈 2)。
- ポリシーの影響を受けるApache Atlasオブジェクトをフィルタリングするために使用する基準を定義する必要があります。”*”のようなワイルドカード表記を使用できます。データコンシューマーが finance という単語で始まる分類のみを検索するように制限するには、FINANCE* (注釈 3) を使用します。
最後に、ポリシーに付与する権限とポリシーによって制御するグループおよびユーザーを定義します。この例では、group:financeとuser:joe_analystにRead Type権限を適用し、user:etl_userに Create Type と Read Type 権限を適用します(注釈 4)。
これで、FINANCE* に一致する分類に対する Create Type 権限を持っているため、データキュレーターの etl_user は “FINANCE_WW”という新しい分類タグを作成し、このタグをその他のエンティティに適用することができます。これは、特定のデータ資産へのアクセスを提供するために、タグベースのアクセスポリシーが別の場所で定義されている場合に便利です。
1.2 データキュレーター - etl_user user
これで、分類ポリシーがetl_userに対してどのように適用されるかを示すことができます。このユーザーはfinanceという単語で始まる分類しか見ることができませんが、その部門に属するさまざまなチームに追加で作成することもできます。
etl_userは、新しい分類タグFINANCE_WWを親分類タグFINANCE_BUの下に作成できます。
Atlasで分類を作成するには:
 画像4 - Atlas分類タブ
画像4 - Atlas分類タブ
- まず、分類パネルボタン(注釈 1)をクリックして、ユーザーがアクセスできる既存のタグを表示します。選択した分類でタグ付けされた資産が表示されます(注釈 3)。
次に、”+”ボタンをクリックして、新しい分類を作成します(注釈 2)。
新しいウィンドウが開き、新しい分類を作成するための様々な詳細情報が要求されます。
 画像5 – Atlas分類作成タブ
画像5 – Atlas分類作成タブ
- まず、分類の名前(この例ではFINANCE_WW)を入力し、同僚がその分類の使い方を理解できるように説明を入力します。
- 分類は階層を持つことができ、階層は親分類から属性を継承します。階層を作成するには、親タグの名前(この例ではFINANCE_BU)を入力します。
- カスタム属性を追加して、後に属性ベースのアクセス制御(ABAC)ポリシーで使用することもできます。これはこのブログ記事の範囲外ですが、このテーマに関するチュートリアルはこちらにあります。
[オプション] この例では、”country”という属性を作成することができますが、これは単にアセットの整理に役立ちます。便宜上、この属性を “string”(フリーテキスト)タイプにすることもできますが、実際のシステムでは、ユーザーの入力が有効な値のセットに制限されるように、おそらく列挙を定義することになるでしょう。
“create”ボタンをクリックすると、新しく作成された分類がパネルに表示されます:
 画像6 – Atlas分類ツリー
画像6 – Atlas分類ツリー
これでトグルボタンをクリックして、タグをツリーモードで見ることができ、両方のタグ間の親/子の関係を見ることができます。
分類をクリックすると、親タグ、属性、現在その分類でタグ付けされている資産など、すべての詳細が表示されます。
1.3データコンシューマ - joe_analyst user
分類の承認プロセスの最後のステップは、データコンシューマーの役割から、制御が適切に実行され、ポリシーが正しく適用されていることを検証することです。
user joe_analystでログインに成功した後:
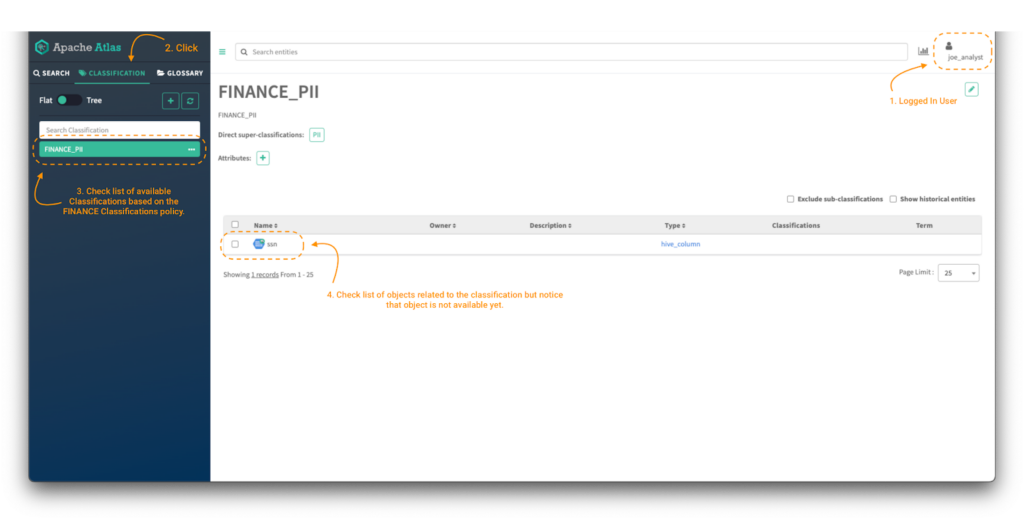 画像7 - 財務データコンシューマーのAtlas分類
画像7 - 財務データコンシューマーのAtlas分類
ポリシーが適用され、ポリシーで定義する権限レベルに基づいてFINANCEという単語で始まる分類のみにアクセスできることを検証するには、分類タブ (注釈 2) をクリックし、使用可能なリストを確認します(注釈 3)。
ここで、エンティティのコンテンツにアクセスできるようにするには(注釈 4)、ビジネス要件に基づいて、Atlasエンティ ティタイプのカテゴリと、対応するレベルの権限で特定のエンティティにアクセスできるようにする必要があります。次のセクションでは、まさにそのことについて触れます。
2. エンティティタイプ、ラベル、ビジネスメタデータの権限付与
このセクションでは、データガバナンス戦略において重要な、Atlasに存在する追加タイプのオブジェクト、具体的にはエンティティ、ラベル、ビジネスメタデータの保護方法についてご説明します。
Apache Atlasのエンティティは”type”の特定のインスタンスであり、プラットフォーム内のデータ資産を表す中核的なメタデータオブジェクトです。例えば、あなたのレイクハウスに “sales_q3”というIcebergテーブルフォーマットで保存されたデータテーブルがあるとしましょう。これは、Apache Atlasでは “Iceberg table”というエンティティタイプと、そのエンティティタイプの特定のインスタンスである “sales_q3”という名前のエンティティによって反映されます。Clouderaプラットフォームにはデフォルトで多くのエンティティタイプが設定されており、あなたが新しいエンティティタイプを定義することもできます。エンティティタイプや特定のエンティティへのアクセスは、Rangerポリシーによって制御することができます。
ラベルは、エンティティに関連付け、その他のエンティティに再利用できる単語またはフレーズ(文字列)です。ラベルは、エンティティに情報を追加する軽量な方法で、エンティティを簡単に見つけ、エンティティに関する知識を他の人と共有することができます。
ビジネスメタデータは、admin user(例えば、データスチュワード)によって事前に定義された、関連するキーと値のペアのセットです。ビジネスメタデータは、メタデータエンティティの整理、検索、管理に役立つビジネスの詳細をキャプチャするために使用されることが多いため、このような名前が付けられています。例えば、マーケティング部門のスチュワードはキャンペーンの一連の属性を定義し、これらの属性を関連するメタデータオブジェクトに追加することができます。対照的に、データ資産に関する技術的な詳細は、通常、エンティティインスタンスの属性としてより直接的にキャプチャされます。これらはデータレイクハウスまたはウェアハウス内のデータセットを監視するプロセスによって作成および更新され、特定のCloudera 環境では通常カスタマイズされません。
このような背景をご説明した上で、エンティティのさまざまなメタデータを追加、更新、または削除できる人を制御するポリシーの設定に移ります。ラベルとビジネスメタデータの両方に対して、分類だけでなく、きめ細かいポリシーを別々に設定することができます。これらのポリシーは、データキュレーターとコンシューマーが行う業務を制御するために、データスチュワードによって定義されます。
2.1データスチュワード - admin user
まず、ユーザーがシステムのエンティティタイプにアクセスできるようにすることが重要です。これにより、特定のエンティティを探すときに、検索をフィルタリングできるようになります。
そのためには、ポリシーを作成する必要があります:
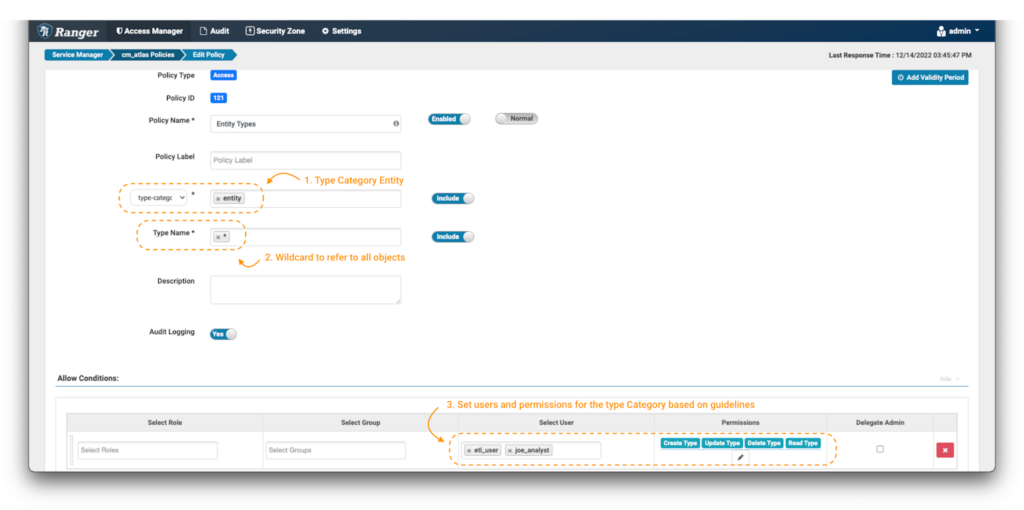 画像8 - Atlasエンティティ・タイプ・ポリシー
画像8 - Atlasエンティティ・タイプ・ポリシー
ポリシーの作成ページで、前述のように名前とラベルを定義します。次に、type-category”entity”(注釈 1)を選択します。ワイルドカード表記 (*) (注釈 2) を使用して、すべてのエンティティタイプを表示し、利用可能なすべての権限をetl_userとjoe_analystに付与します (注釈 3)。これで、これらのユーザーは、システム内のすべてのエンティティタイプを閲覧できるようになります。
次のステップは、データコンシューマーjoe_analystに、finance分類タグを持つエンティティの読み取りアクセスだけを許可することです。これで、このユーザーがプラットフォームで閲覧できるオブジェクトが制限されます。
これを行うには、前のセクションで示したのと同様のプロセスに従ってポリシーを作成する必要がありますが、ポリシーの詳細については若干変更する必要があります:
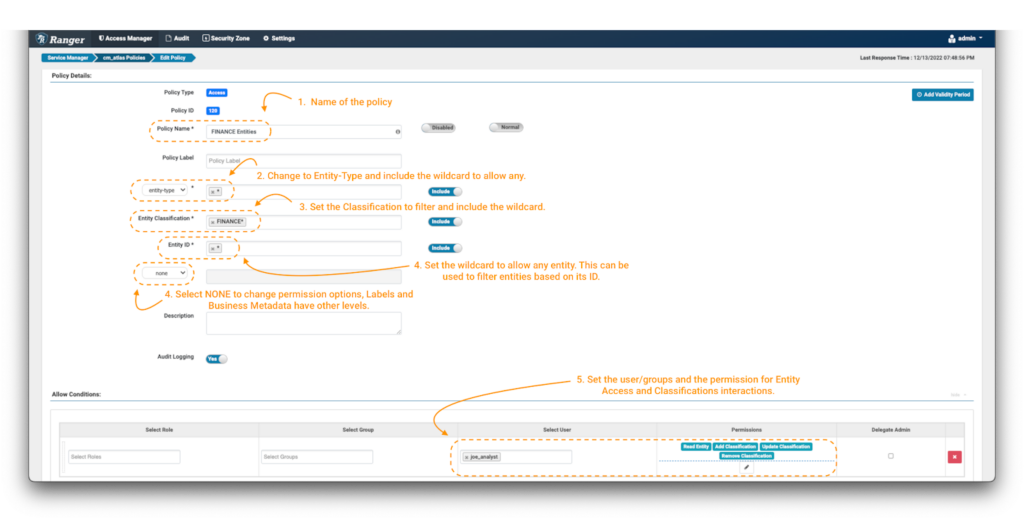 画像9 - Atlas 財務エンティティポリシーの例
画像9 - Atlas 財務エンティティポリシーの例
- いつものように、後で簡単に管理できるようにポリシーに名前(とラベル)を付けます。
- 最初に行う重要な変更は、ポリシーを”type-category”ではなく”entity-type”に適用することです。ドロップダウンメニューで”entity-type”を選択し(注釈 2)、ワイルドカードを入力して、すべてのエンティティタイプに適用します。
- いくつかの追加フィールドがフォームに表示されます。エンティティ分類フィールドでは、制御したいエンティティに存在するタグを指定できます。この例では、”finance”で始まる単語でタグ付けされたオブジェクトのみを許可します。FINANCE*という表現を使用します(注釈 3)。
- 次に、エンティティIDフィールドで制御するエンティティをフィルタリングします。この演習では、ワイルドカード (*) (注釈 4) を使用し、追加フィールドには “none”を選択します。このボタンで、条件パネルで強制できる権限のリストが更新されます(注釈 4)。
- データコンシューマーとして、joe_analyst userにエンティティを閲覧できるようにします。これを実装するには、Read Entity権限を選択します(注釈 5)。
- データキュレーターetl_userに新しい条件を追加しますが、今回はタグを適切に変更するための権限を含めるために、特定のユーザーにAdd Classification、Update Classification、Remove Classification権限を追加します。
このように、分類タグのような追加のメタデータオブジェクトを使用して、特定のエンティティへのアクセスを制御することができます。Atlasは、プラットフォームに登録されたエンティティをリッチ化するだけでなく、これらのオブジェクトに対するガバナンス戦略を実装し、誰がアクセスしたり変更したりできるかを制御するために使用できる、その他のメタデータオブジェクトをいくつか提供しています。これはラベルとビジネスメタデータの例です。
誰がラベルを追加したり削除したりできるかを制御したい場合:
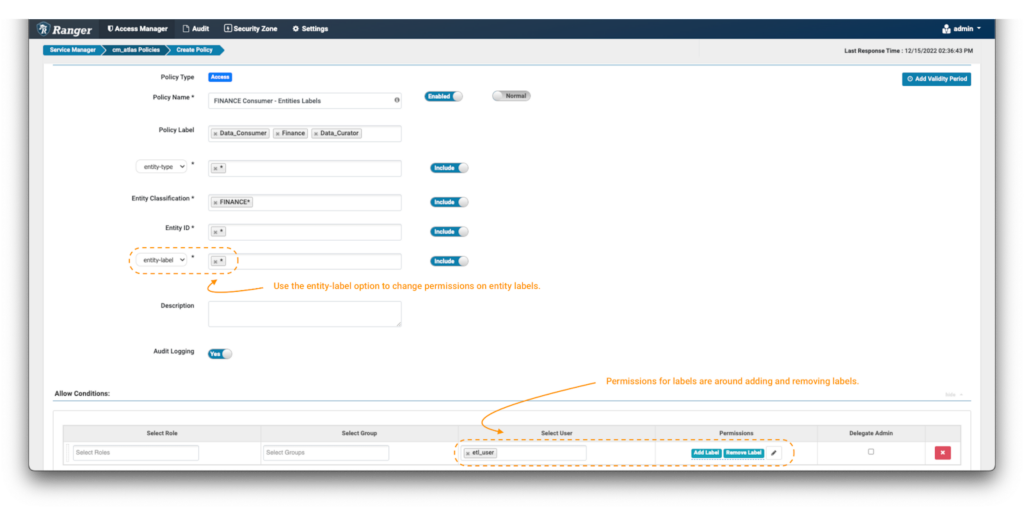 画像 10 - Atlas財務ラベルポリシーの例
画像 10 - Atlas財務ラベルポリシーの例
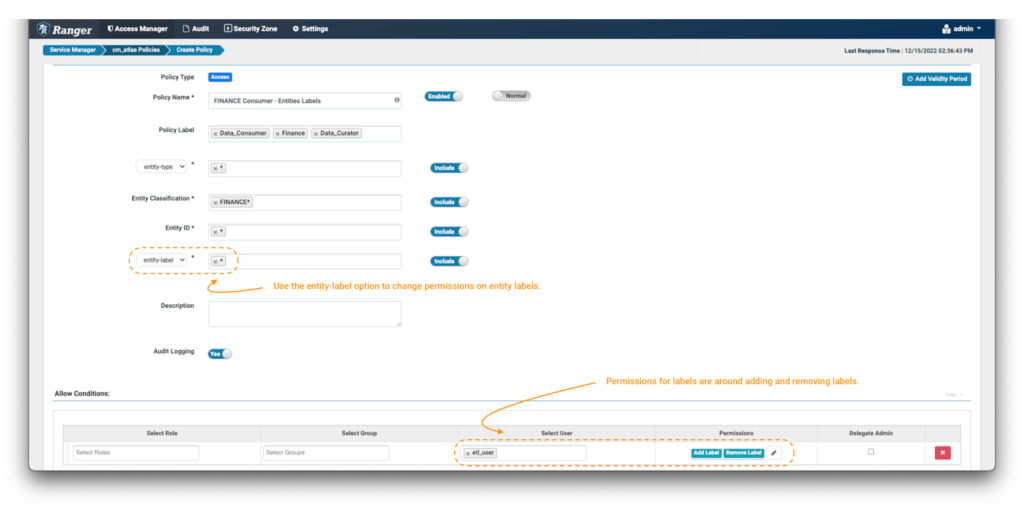
- ラベルに対するポリシーの設定と前述の例で唯一異なるのは、画像に示すように、追加フィールドフィルターを “entity-label”に設定し、制御したいラベルの値を入力する点です。この例では、ワイルドカード (*) を使用して、FINANCE*分類でタグ付けされたすべてのエンティティのラベルに対する操作を有効にします。
- ドロップダウンからエンティティラベルを選択すると、権限リストが更新されます。Add Label & Remove Label権限を選択して、データキュレーターにエンティティからラベルを追加および削除するオプションを付与します。
同じ原理をビジネスメタデータの権限を制御するために適用できます:
 画像 11 - Atlas財務ビジネス・メタデータ・ポリシーの例
画像 11 - Atlas財務ビジネス・メタデータ・ポリシーの例
- この例では、画像に示すように追加フィールドフィルターを “entity-business-metadata”に設定し、保護したいビジネスメタデータ属性の値を入力します。この例では、ワイルドカード (*) を使用して、FINANCE*分類でタグ付けされたエンティティのすべてのビジネスメタデータ属性に対する操作を有効にします。
- entity-business-metadataドロップダウンを有効にすると、権限リストが更新されます。Update Business Metadata権限を選択して、データキュレーターに財務エンティティのビジネスメタデータ属性を変更するオプションを付与します。
Apache RangerがApache Atlasオブジェクトに対して提供するきめ細かいアクセス制御の一部として、エンティティIDを使用して制御したいオブジェクトを正確に指定するポリシーを作成することができます。上記の例では、”all entities”を参照するためにワイルドカード(*)を頻繁に使用しましたが、以下では、よりターゲットを絞った使用例をお見せします。
このシナリオでは、”World Wide Bank”という特定のプロジェクトの一部であるデータテーブルに関するポリシーを作成しようと思います。基準として、プロジェクトのオーナーは、すべてのテーブルを”worldwidebank”というデータベースに格納することを求めています。
この要件を満たすために、ClouderaのApache Atlasのディストリビューションにあらかじめ設定されているエンティティタイプの1つ、すなわち “hive_table”を使用することができます。このエンティティタイプでは、識別子は常にテーブルが属するデータベースの名前で始まります。Ranger式を使用して、”World Wide Bank”プロジェクトに属するすべてのエンティティをフィルタリングすることができます。
worldwidebankエンティティを保護するポリシーを作成するには:
 画像 12 - Atlas “Worldwide Bank”エンティティポリシーの例
画像 12 - Atlas “Worldwide Bank”エンティティポリシーの例
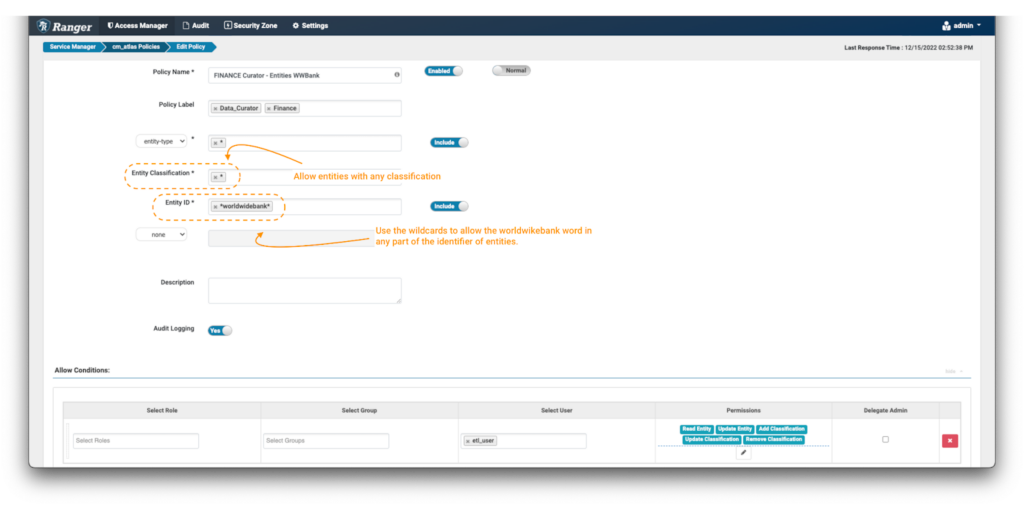
- 新しいポリシーを作成しますが、今回はエンティティ分類を何も指定せず、ワイルドカード”*”式を使用します。
- エンティティIDフィールドに式を使用します: *worldwidebank*
- Conditionsで、データキュレーターetl_userにRead Entity、Update Entity、Add Classification、Update Classification、Remove Classificationの権限を選択し、これらのエンティティの詳細を表示したり、必要に応じてリッチ化/変更/タグ付けしたりできるようにします。
2.2データキュレーター - etl_user user
財務データコンシューマーのjoe_analystがworldwidebankプロジェクトのエンティティを使用・アクセスできるようにするには、データキュレーター etl_userが承認された分類でエンティティにタグを付け、必要なラベルとビジネスメタデータ属性を追加する必要があります。
Atlasにログインし、手順に従って適切なエンティティにタグを付けます:
 画像 13 - データキュレーターのエンティティ検索
画像 13 - データキュレーターのエンティティ検索
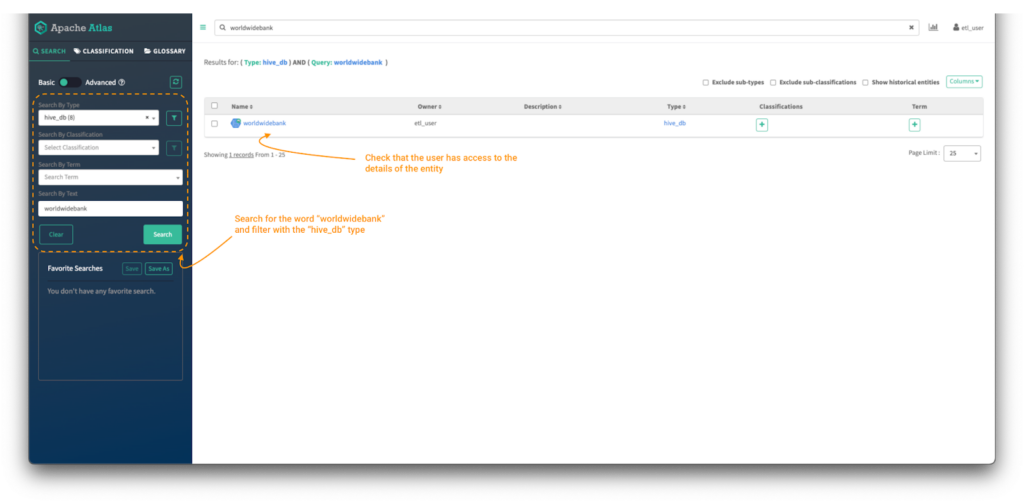
- まず、検索バーを使ってworldwidebankの資産を検索します。左側のパネルにある”search by type”フィルタを使用して、検索対象を”hive_db”エンティティタイプに限定することもできます。
- データキュレーターとして、worldwidebankデータベースエンティティの詳細が閲覧でき、アクセスが許可されているはずです。エンティティオブジェクトへのクリック可能なリンクがあるはずです。
- エンティティオブジェクトをクリックすると、その詳細が表示されます。
エンティティ名をクリックすると、エンティティの詳細ページが表示されます:
画像 14 – Worldwide Bankデータベースのエンティティ詳細
画面上部には、エンティティに割り当てられている分類が表示されます。この例では、タグは割り当てられていません。ここで”+”記号をクリックしてタグを割り当てます。
“Add Classification”画面では:
 画像 15 - Worldwide Bankデータベース・タグ・プロセス
画像 15 - Worldwide Bankデータベース・タグ・プロセス
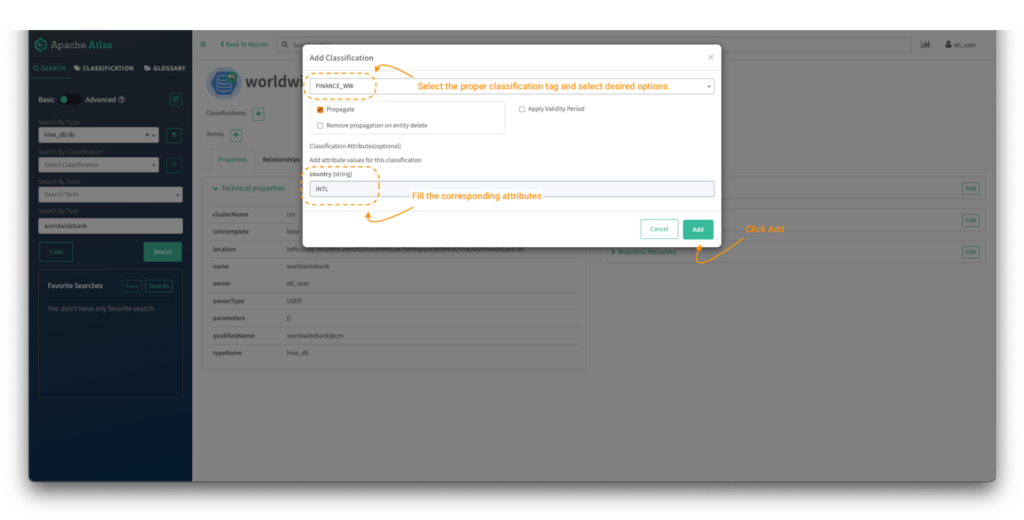
- FINANCE_WWタグを検索し、選択します。
- 分類タグに属性がある場合は、適切な属性を入力します(上記の”1.2 データキュレーター – etl_user user ”セクションの画像 5 のオプション)。
- “add”をクリックします。
これで、選択した分類にエンティティがタグ付けされます。
ここで、worldwidebank hive_dbエンティティを新しいラベルと “Project”という新しいビジネスメタデータ属性でリッチ化します。
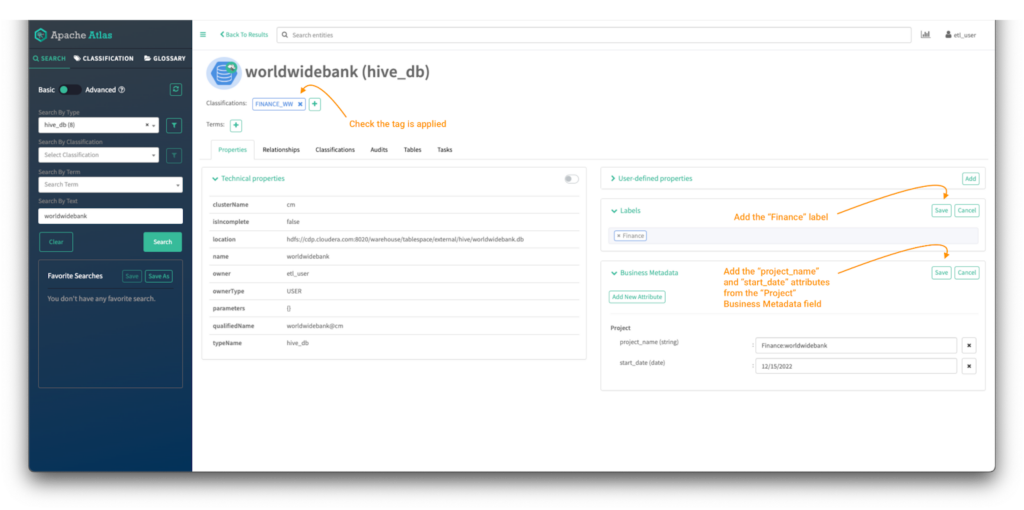 画像 16 -Worldwide Bankデータベースのタグ付けプロセス
画像 16 -Worldwide Bankデータベースのタグ付けプロセス
ラベルを追加するには、ラベルメニューの”Add”をクリックします。
- ラベルをスペースに入力し、”save”をクリックします。
ビジネスメタデータ属性を追加するには、ビジネス・メタデータ・メニューの “Add”をクリックします。
- 属性が割り当てられていない場合は “Add New Attribute”を、既に割り当てられている場合は”edit”をクリックします。
- 追加したい属性を選択し、詳細を記入して”save”をクリックします。
注:ビジネスメタデータの属性の作成はブログには含まれていませんが、手順はこちらに従ってください。
“worldwidebank”Hiveオブジェクトに “FINANCE_WW”分類のタグが付けられると、データコンシューマーはそのオブジェクトにアクセスして詳細を見ることができるようになります。また、データコンシューマーが、”finance”で始まる分類でタグ付けされた他のすべてのエンティティにアクセスできることを確認することも重要です。
2.3データコンシューマー - joe_analyst user
ポリシーが正しく適用されていることを検証するために、Atlasにログインします:
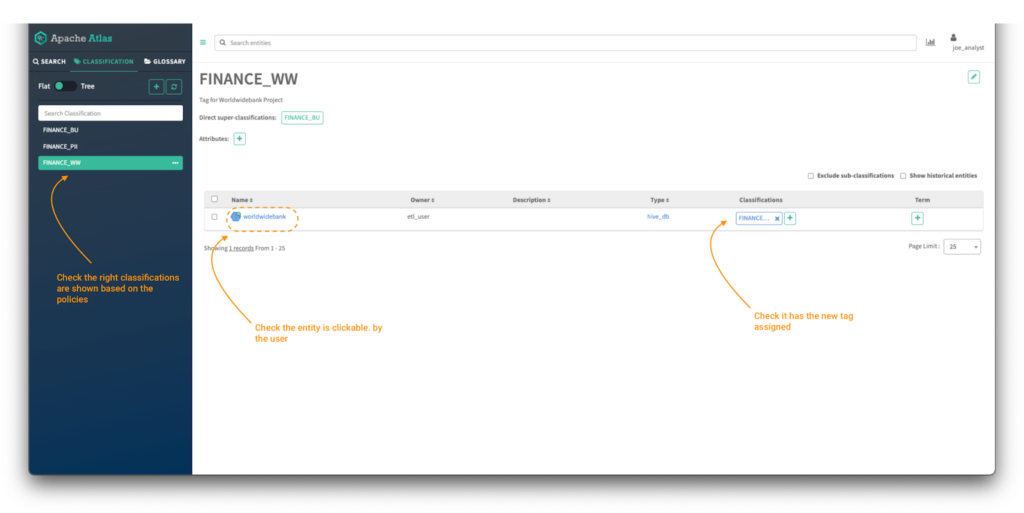 画像 17 – 財務データ資産
画像 17 – 財務データ資産
分類タブをクリックし、検証します:
- 前のステップで作成したポリシーに基づいて表示されるタグのリスト。すべてのポリシーは”finance”で始まらなければなりません。
FINANCE_WWタグをクリックし、”worldwidebank”hive_db オブジェクトへのアクセスを検証します。
“worldwidebank”オブジェクトをクリックした後:
画像 18 – WorldWideBankデータベース資産の詳細
前のステップで財務データキュレーターによってリッチ化された資産の詳細がすべて見られます:
- 資産のすべてのテクニカルプロパティが表示されているはずである
- 資産に適用されたタグが表示されているはずである
- 資産に適用されたラベルが表示されているはずである
- 資産に割り当てられたビジネスメタデータの属性が表示されているはずである
3. 用語集および用語集の用語の権限
このセクションでは、データスチュワードがポリシーを作成して、用語集と用語集の用語に対するきめ細かなアクセス制御を許可する方法をご説明します。これにより、データスチュワードは誰が用語集にアクセス・リッチ化・変更できるかを制御し、不正アクセスやミスからコンテンツを保護することができます。
用語集は、ビジネスユーザーに適切な語彙を提供し、用語 (単語) 同士を関連付け、異なるコンテキストでも理解できるように分類します。これらの用語は、後にデータベース、テーブル、カラムなどのエンティティに適用することができます。これにより、リポジトリに関連する専門用語が抽象化され、ユーザーはより馴染みのある語彙でデータを見つけ、扱うことができます。
用語集や用語に分類タグを付けることもできます。この利点は、用語集の用語がエンティティに適用されると、用語の分類がエンティティにも適用されることです。データ・ガバナンス・プロセスの観点からは、これは、ビジネスユーザーが用語集に記録された独自の用語を使用してエンティティの内容をリッチ化でき、分類も自動的に適用できる、ということであり、これまで見てきたように、アクセス制御を定義する際に使用される、より”technical”なメカニズムです。

まず、データスチュワードとして、名前に特定の単語を含む用語集オブジェクトへの読み取りアクセスを付与するポリシーを作成し、データコンシューマーが特定のコンテンツへのアクセスが許可されていることを検証できる方法をお見せします。
3.1データスチュワード – admin user
用語集と用語へのアクセスを制御するポリシーを作成するには、以下のようにします:
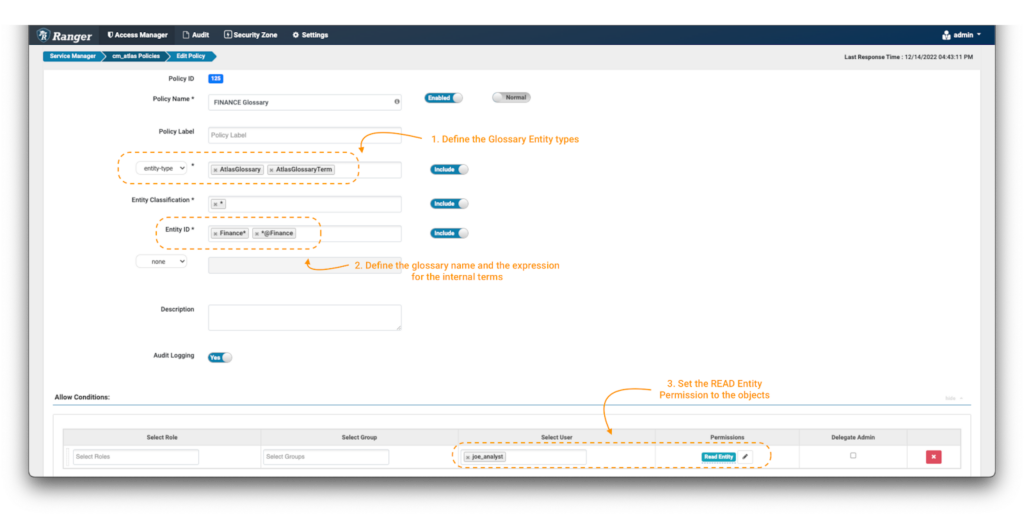 画像 19 - 用語集制御ポリシー
画像 19 - 用語集制御ポリシー
- 新しいポリシーを作成しますが、今回は”entity-type”の AtlasGlossaryとAtlasGlossaryTermを使用します(注釈 1) 。
- エンティティ分類フィールドで、ワイルドカード表現:*を使用します。
- エンティティIDは、保護したい用語集と用語を定義できる場所です。Atlasでは、用語集の用語はすべて、名前の最後に”@”を付けて参照します(例:term@glossary)。”Finance”用語集そのものを保護するには、Finance*を、用語そのものを保護するには、*@Financeを使用します(注釈 2)。
- Conditionsで、データコンシューマーjoe_analystに用語集とその用語が表示されるように、Read Entity権限を選択します(注釈 3)。
3.2データコンシューマー - joe_analyst user
“Finance”用語集オブジェクトのみにアクセスできることを検証します:
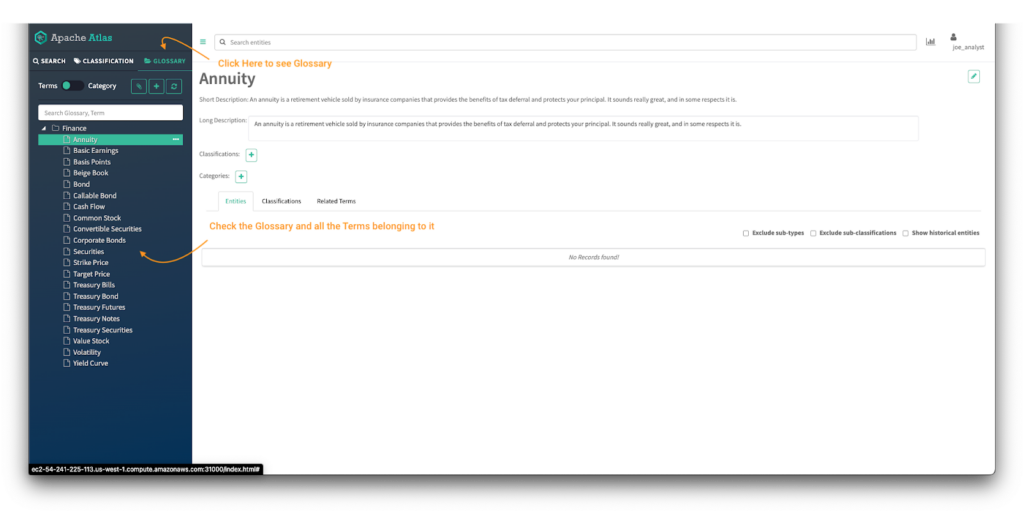 画像20 - 財務Atlas用語集
画像20 - 財務Atlas用語集
- Atlasパネルで glossaryタブをクリックする
- Atlas UIで利用可能な用語集と、用語集の用語の詳細へのアクセスを確認する
まとめ
この記事では、組織が、SDXの基本的かつ不可欠なコンポーネントであるApache AtlasとApache Rangerの両方を活用して、Clouderaプラットフォームのデータ・ガバナンス・コンポーネントに対してどのようにきめ細かいアクセス制御戦略を実装できるかをご紹介しました。ほとんどの組織には、 データアクセスに対する成熟したアプローチがありますが、メタデータを制御することは、仮に考慮されていたとしても、あまり定義されていないのが一般的です。この記事で共有されている洞察とメカニズムは、データならびにメタデータのガバナンスに対するより全面的なアプローチの実装に役立ちます。このアプローチは、データ・ ガバナンス・コンポーネントが重要な役割を果たすコンプライアンス戦略のコンテキストにおいて非常に重要です。
SDXの詳細についてはこちらをご覧下さい。また、具体的なデータガバナンスのニーズについては、ぜひ当社にお問い合わせください。

