
この記事は、2025/4/22に公開された「What no one tells you about RAG」の翻訳です。
RAG アプリケーションの構築 - 細部に宿る課題
検索拡張生成(RAG)アプリケーションの構築は、データ・インジェスチョン (データ採取)、処理、検索を慎重に扱う必要があり、すぐに複雑化する可能性があります。従来、開発者はデータのチャンク化、埋め込みの挿入、ベクターデータベースの統合といった工程を順に進めてきました。
しかし、RAG ソリューションを実装する際によくある落とし穴の1つは、これらのコンポーネントが相互に依存していることを理解していない点です。開発者は、「このデータはそのままチャンク化できるのか、それともチャンク化する前に精査すべきか?」という問いを投げかける必要があります。
Cloudera Data Flow と Cloudera 独自の RAG パイプラインプロセッサは、非構造化データをパーティション分割によって精製し、より効果的なチャンク化と高品質なベクター埋め込みを実現することで、複雑な処理を簡素化します。不適切に設計されたパーティション分割やチャンク化は、パフォーマンスや埋め込みの品質を損なう可能性がありますが、Clouderaのツールはこれらの複雑さの多くを抽象化し、効率的で信頼性の高い RAG ソリューションの開発を容易にします。
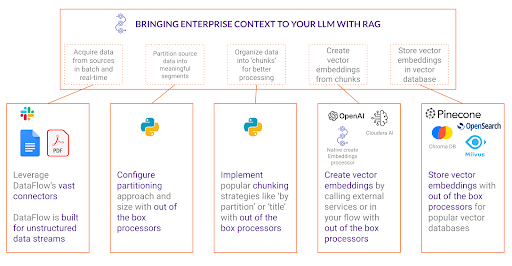
RAG ワークフローの重要な段階( パーティション分割、チャンク化、埋め込み、挿入)を順に見ていき、Cloudera のテクノロジーがそれぞれの工程をどのように簡素化するかをご紹介します。
データパーティション分割:RAG の基盤
RAG ワークフローの最初の重要なステップは、パーティション分割です。このプロセスでは、大規模で時には非構造化データソースを意味のあるセグメントに分割し、非構造化データをプログラム的に反復処理できるようにします。もちろん、パーティション分割を行わなくても検索プロセス自体は可能ですが、処理をより細かく制御できるほど、さまざまなデータソースに対応したフローを柔軟に構築できます。パーティション分割によって、データはユーザーのクエリ方法に沿った、扱いやすい単位に構造化されます。
パーティション分割の戦略は、データの性質によって異なります。たとえば、セクションの見出しごとにパーティション分割することで、ユーザーマニュアルのような長文ドキュメントを処理する際に、より整理された検索が可能になります。対照的に、チャットログのような会話データの場合は、会話の流れを保つためにタイムスタンプごとに内容を分割することがあります。もう1つの重要な考慮点はトークン制限です。ほとんどの埋め込みモデルには、一度に処理できるトークンサイズがあらかじめ定められているため、最適なパフォーマンスを確保するには、パーティション分割をこれらの制約に合わせる必要があります。
明確に定義されたパーティション分割のアプローチは、RAG アプリケーションの精度、効率性、使いやすさを維持するのに役立ちます。開発者は、最も関連性の高いデータのみを取得して LLM に渡し、不要な計算負荷を最小限に抑えることで、応答品質を最適化できます。
チャンク化:コンテキストの保持を確保
パーティション分割が完了したら、次のステップはチャンク化です。チャンク化とは、関連するパーティションをまとめて、意味のあるコンテキストを維持することです。パーティション分割がコンテンツを基本的な要素に分割するのに対し、チャンク化はそれらの要素間の関係性を保ち、コンテキストの欠落を防ぎます。
たとえば、法的文書では、条項や規定が複数の段落にわたることがあります。これらを細かく分割しすぎると、ユーザーのクエリに基づいてコンテンツを検索する際に、意味が失われる可能性があります。チャンク化は、関連するテキストセグメントを、まとめて論理的に完結した単位にすることで機能します。これにより、ユーザーがクエリを実行した際、モデルは十分なコンテキスト情報を受け取り、正確で適切な応答を生成できるようになります。
チャンク化の戦略は、データセットの性質によって異なります。中には、あらかじめ定められたトークン数に基づいてセグメントをまとめる、シンプルな固定長のチャンク化を用いる方法もあります。さらに高度な戦略としては、ドキュメントのタイトルを関連するテキストと一緒にチャンク化する方法があります。
効果的なチャンク化は、検索精度を高め、検索の遅延を最適化し、LLM が生成する応答がコンテキストを踏まえた正確な応答が得られるようにします。さらに、コンテキスト保持を最大化するチャンク化戦略を決定することで、あらかじめ定めたチャンクサイズの情報を基に、埋め込みモデルの判断を支援できます。
埋め込み:テキストを検索可能なベクトルに変換
適切に構造化されたチャンクが配置されたら、RAG ワークフローの次のステップは埋め込みです。埋め込みはテキストを数値で表現したもので、機械がさまざまなテキストセグメントの意味を理解し、比較できるようにします。埋め込みを行わない場合、RAG アプリケーションは単純なキーワード検索に限定され、真の意味でのセマンティック検索に必要なコンテキストの理解が欠如します。
埋め込みは、トークン化、ベクトル変換、保存を含む多段階のプロセスです。テキストチャンクが埋め込みモデルを通過する際、まずトークンに分割されます。これらのトークンは、テキストの本質を捉えた高次元ベクトルに変換され、ユークリッド距離(L2)やコサイン類似度といった数学的な類似度検索に適した形式になります。
適切な埋め込みモデルを選択することは極めて重要です。一部のモデルは汎用的な検索向けに最適化されていますが、他のモデルは法務、医療、技術文書といったドメイン特化型アプリケーション向けに微調整されています。もう1つの重要な考慮事項はベクトルの次元数であり、ベクトルデータベースのスキーマと一致している必要があります。ベクトルサイズが一致していないと、検索の非効率や互換性の問題を引き起こす可能性があります。
テキストチャンクがベクトル表現に埋め込まれると、類似度指標を用いて検索可能になります。これにより、ユーザーのクエリに基づいて最も関連性の高いコンテンツを非常に効率的に検索でき、RAG 搭載アプリケーションの精度と応答性が大幅に向上します。
Cloudera Data Flow は、非常に強力でありながら使いやすい埋め込みプロセッサを提供し、データフローの機能を進化させるとともに、プロセッサのコンテキスト内でモデルを活用できるようにします。API を呼び出す必要はありません(GPUも不要です)。このプロセッサには、次の3つのシンプルなプロパティがあります。
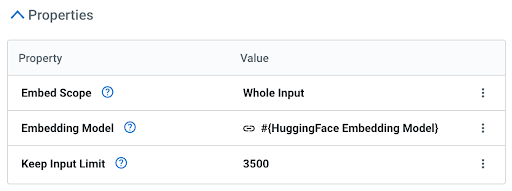
これにより、各データフローに最適な埋め込みモデルを選択できるよう、きめ細かな制御が可能になります。
埋め込みチャンクをベクトルデータベースに挿入することで、効率的な検索を実現
RAG ワークフローの最終ステップは、埋め込み済みチャンクをベクトルデータベースに挿入することです。ベクトルデータベースは、高速な類似度検索を実行できるよう設計されており、ユーザーがクエリを実行した際に、関連性の高いコンテンツを効率的に検索できます。
正確な一致のために構造化インデックスに依存する従来型データベースとは異なり、ベクトルデータベースは、ANN や KNN といったアルゴリズムを用いた類似度検索によって、ユーザーのクエリに近い埋め込みを見つけ出します。これにより、RAG アプリケーションは、クエリの表現が保存されているテキストと異なっていても、意味的に関連性の高いコンテンツを検索できるようになります。
埋め込みデータがベクトルデータベースに挿入されると、システムはリアルタイムでのクエリの実行が可能な状態になります。ユーザーがリクエストを送信すると、クエリは埋め込みに変換され、保存されたベクトルと比較され、最も関連性の高い結果が取得されます。これが LLM の応答の基盤となります。
Cloudera Data Flow は、Milvus、Pinecone、Chroma などの多くの VectorDB 接続プロセッサを提供しており、今後さらに追加される予定です。
今すぐ RAG アプリケーション開発を効率化
Cloudera Data Flow とその専用 RAG パイプラインプロセッサを活用することで、企業はこれまでにないほど容易に RAG アプリケーションを構築、展開、最適化できるようになりました。技術的な複雑さの多くを抽象化し、開発者が扱いやすい形にすることで、Cloudera のソリューションは、検索精度の向上、応答生成の最適化、そして全体的なユーザー体験の改善に集中できる環境を提供します。
企業は、Cloudera の独自のパーティショニング、チャンク化、埋め込み、VectorDB 統合プロセッサを活用することで、効率的にスケールし、正確でコンテキストに応じた応答を提供する RAG ソリューションを迅速に実装できます。
Cloudera が RAG アプリケーション開発の効率化をどのように支援できるか詳しく知りたい方は、当社チームまでデモのご依頼や詳細情報の確認のお問い合わせをお願いします。もしくは、技術ドキュメントをご覧ください。
近日公開予定の高度な RAG 最適化アプローチの詳細解説をお見逃しなく!
さらに詳しく
Cloudera Data Flow 2.9 の新機能の詳細とデータパイプラインの変革に役立つ仕組みについては、こちらのビデオをご覧ください。
