
原文: Using Iceberg Table Format in CDP Public Cloud to Ingest, Process and Analyze Stock Intraday Data
https://community.cloudera.com/t5/Community-Articles/Using-Iceberg-Table-Format-in-CDP-Public-Cloud-to-Ingest/ta-p/337329
概要
データ分析のユースケースにおいて、株式市場はよく使われる例です。Cloudera Data Platformを使用して、迅速な洞察から可視化までをどのように簡単に作成できるでしょうか?
CDPでIcebergテーブルフォーマットを使用して、統合され安全な新機能を利用するのはどうでしょうか?【Cloudera Data Platform における Apache Iceberg の導入】参照。
本日の記事では、Cloudera Public Cloudを使用してREST APIからデータを取得し、クリックやパラメータ入力のみで、データのクエリ、ダッシュボード、および高度な分析を迅速に開始する方法を紹介します。
この例では、下記の手順を行います:
- Cloudera Dataflowを使用して、定期的に(D-1データとして)オブジェクトストレージにイントラデイ株価データをロードします。
- Sparkを使用してデータを処理し、Cloudera Data Engineeringで利用可能にし、Airflowでスケジュールします。
このプロセスでは、テーブルが新しいかどうかをチェックし、その後新しいICEBERG株価テーブルにMERGE INTOします。コードはこちらです。 - Cloudera Data Warehouse/Cloudera Data Visualizationでデータを分析およびクエリします。
- テーブルでTIME TRAVEL/SNAPSHOTS(Icebergの機能)を実行します。
また、Icebergを使用することで、 Schema Evolution を実行し、Parquetなどのオープンフォーマットを使用してオープンソースの最適化やエンジン間の相互運用性を利用することができます。
今回利用する株価情報はD-1ですが、新しい株価ティッカーがパラメータに存在するかどうかを特定するために、10分ごとに実行するスケジュールを設定します。
さらに、すべての操作をコーディングせずに、保存されたテンプレートのみを使用します!
以下が今回のアーキテクチャです:
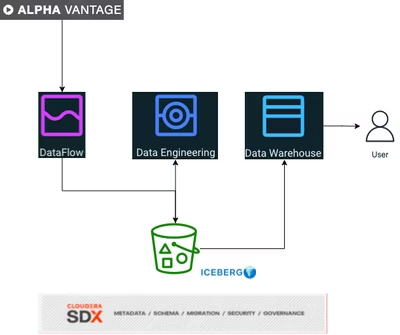
前提条件
株価情報をダウンロードするために、この記事を書いている時点で無料のAPIであるAlpha Vantageを使用します。
まず、使用するAPIキーを取得するために登録が必要です。そのAPIキーを保存してください。
また、データを保存するバケットのパス名も必要です。必要な情報(AWS APIキー、Bucket)が揃ったので、始めましょう!
以下は、入力が必要なパラメータのリストです:
- Alpha Vantage API Key;
- Root Bucket used by CDP;
- Workload username;
- Workload password;
今回利用するCloudera Data Platformのコンポーネントは以下の通りです:
- Cloudera Data Warehouse;
- Cloudera Dataflow;
- Cloudera Data Engineering(Spark 3);
REST APIで株価データをオブジェクトストレージに取り込むデータフローを作成する
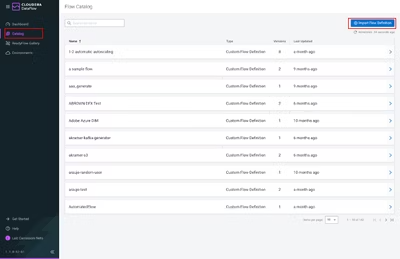
- まず、ここにあるテンプレートファイルをダウンロードして、Cloudera DataFlowにアクセスします。そこでテンプレートをアップロードし、オブジェクトストレージにデータのロードするデータフローをインポートします。
- Cloudera Dataflow UIで、「Catalog」→「Import Flow Definition」をクリックします。
3) フローに名前を付け、説明を追加し、ダウンロードしたCDFテンプレートファイルを選択してください。
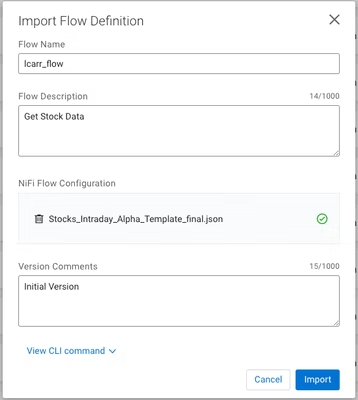
4) Importをクリック;
5) デプロイした後、フローを選択し、メニューから青いボタン (Deploy)をクリックしてください:
6) この後使いたいCDPフロー環境(Environment)を選択し、次に進んでください:
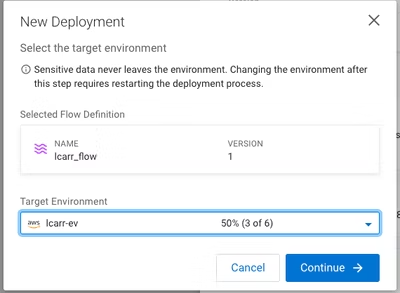
7) デプロイメント名を入力して「次へ」をクリックします。
8) NiFiの設定は変更せずに「次へ」をクリックします。
9) 次に、提供が必要なパラメーターを求められますので、以下の情報を入力してください:
- CDP Password: CDPのワークロードパスワード
- CDP User: CDPのワークロードユーザー (Workload user in CDP)
- S3 Path: CDPが使っている/user//のは以下に作成されるサブフォルダ(S3などの名前Prefixは除く)
- S3 Bucket: CDPが使っているbucket (s3などのPrefixは除く)
- API Alpha Key: 使用されるAlpha APIキー(デモはIBMの株データのみ取得可能)
- Stock_list: ロードしたい株のリスト、各行に株のティッカーを記入します
Note: デプロイ後に株リストを変更し、新しいティッカーデータを取り込むことが可能です。これはIcebergのタイムトラベル機能をデモンストレーションするために行います。.
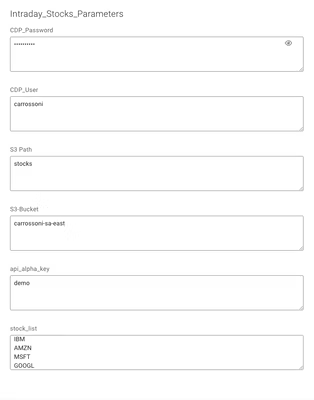
10)Nextボタンをクリックし、クラスタサイズとNiFi node、Auto Scalingの範囲を選ぶ:
11)KPI数値を定義。今回はデフォルト設定のままで進みます。
12)最終確認して、Deployボタンをクリック。
これで作業完了!数分以内に指定したBucketに株価情報が届きます。
下記パスで、バケットの内容を確認できます:
s3a:///user///new:
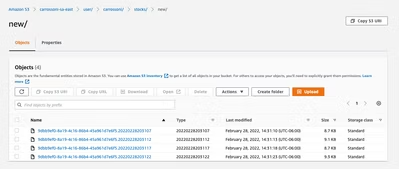
Icebergテーブルを作成
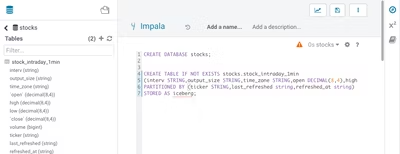
Icebergテーブルを作成ためには、CDP内のSDXに接続されたImpalaバーチャルウェアハウス(Virtual Warehouse)で下記テーブルを作成するスクリプトを使用します:
CREATE DATABASE stocks;
CREATE TABLE IF NOT EXISTS stocks.stock_intraday_1min
(
interv STRING,
output_size STRING,
time_zone STRING,
open DECIMAL(8, 4),
high DECIMAL(8, 4),
low DECIMAL(8, 4),
close DECIMAL(8, 4),
volume BIGINT
)
PARTITIONED BY (ticker STRING,last_refreshed string,refreshed_at string)
STORED AS iceberg;
Cloudera Data Warehouse UIにアクセスしてHueを開き、クエリでIcebergテーブルを作成しましょう:
Hueを開いたままにして、後でデータをクエリします。
注:この例および次の例では、データベース名を「stocks」に変更しています。
CDEを使用してIcebergの処理と取り込みを行う
これから、Cloudera Data Engineeringを使用してオブジェクトストレージのファイルをチェックし、新しいデータかどうかを比較し、それをIcebergテーブルに挿入します。
これを行うには、jarをダウンロードし、Cloudera CDE UIで仮想Sparkクラスタに移動し、「View Jobs」をクリックします。
Step1. Jobs リンクをクリック → Create Jobsボタンをクリック:

- Name: Job名を入力。 例: StockIceberg
- File: Jarファイルをアップロード。例:stockdatabase_2.11-1.0.jar (drop-down buttonからCreate a resourceを選ぶ)
- Main Class : com.cloudera.cde.stocks.StockProcessIceberg
- Arguments: パラメータ
- → (例: stocks)
- → (Dataflowが利用しているBucketと同じ 例: s3a://carrossoni-sa-east/)
- → (Dataflowが利用しているPathと同じ 例: stocks)
- → (Dataflowが利用しているUserと同じ 例: carrossoni)
Step2. Schedule: Scheduleを有効にして、10分毎に実行するように設定。
*/10 * * * *
このジョブは10分ごとに実行され、証券データの新しいティッカーがあるかどうかを確認します。一回目の実行には、ジョブのアクションの下にある3つの点をクリックし、「Run Now」をクリックします。
「Job Runs」をクリックして、ジョブが完了したかどうかを確認します。
Kubernetesでリソースを起動し、パイプラインを実行して最終テーブルに新しいデータを取り込むのに約3分かかります。

クラスターをチェックすることもできます:

このアプリケーションは非常にシンプルで、下記作業を行います:
- 新しいディレクトリ内の新しいファイルをチェックします。
- Spark内に一時テーブルを作成し、このテーブルをキャッシュして重複行を特定します(NiFiが同じデータを再度ロードした場合)。
- 出力目標テーブルにMERGE INTOを実行し、新しいデータをINSERTまたは存在する場合はUPDATEします。
- バケット内のファイルをアーカイブします。
実行後、処理されたファイルはバケット内の「processed」+日付のディレクトリにあります。
つきましては、データをクエリしてみましょう!
HueとCloudera Data VisualizationでIcebergテーブルをクエリする
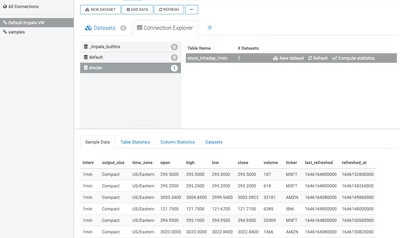
上記操作でデータの取り込みが完了したはずですので、Hue画面に戻ってテーブルstocks.stock_intraday_1minでデータをアクセスしましょう。
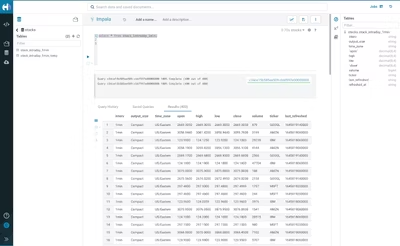
Cloudera Data Visualizationでは、このテーブルを選択して新しいデータセット「Stocks」を作成し、可視化もできます。
たとえば、出来高による株価の可視化などが可能です。
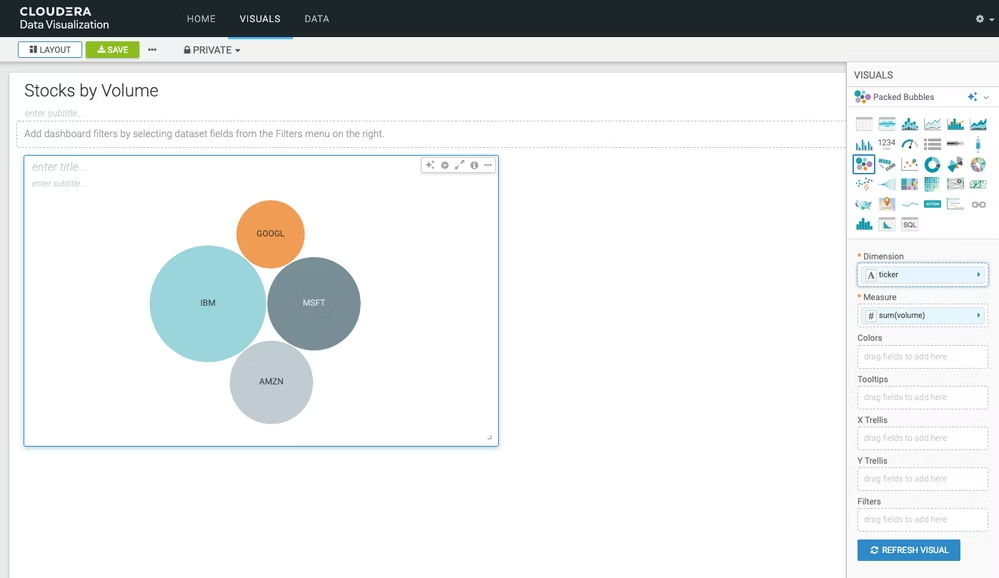
また、Cloudera CDPツールを使用して他のソースからデータを取り込み、独自の株価分析プラットフォームを作成することもできます。
Icebergの高度な機能
Apache Icebergには下記代表的な機能があります:
- タイムトラベル
- スキーマ進化
- パーティション進化
これに加えて、他にも多くの利点があります。
また、クエリエンジンに依存せず、各エンジンがネイティブに実装している最適化を利用します。
今回の例では無料のAPIがリアルタイムのデータを提供しないため、日単位の株価データをロードします。
しかし、Cloudera Dataflowのパラメータを変更して、さらに1つのティッカーを追加し、CDEプロセスを毎時実行するようにスケジュールします。
その後、Icebergを使用して新しいティッカー情報をダッシュボードで確認したり、タイムトラベルも使ってみます。
まずはCloudera Dataflowに移動し、ダッシュボードで展開したフローをクリックして、デプロイメントの管理(Manage Deployment)をクリックします。
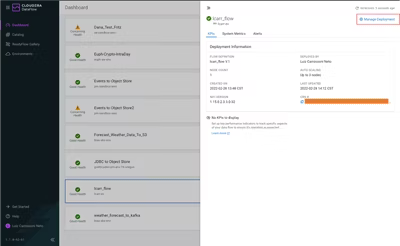
次に、パラメータ(Parameters)をクリックします。
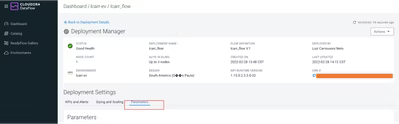
スクロールして、stock_listを変更して新しいティッカーを追加します。
私はNVDAティッカーを追加しますが、他のティッカーを選択しても構いません。これを行った後、【変更を適用】 (Apply Changes)をクリックします。
フローが再度デプロイされ、1分ごとに実行されます。
後で、CDEプロセスが定期的に実行されるため、新しいティッカーがIcebergテーブルにロード/処理されたかどうかを確認できます。
数分後(スケジュールされた10分間)に、次のクエリを使用してテーブルのスナップショットを確認できます。
DESCRIBE HISTORY stocks.stock_intraday_1min;
Sparkプロセスが何回か実行されたので、それぞれの実行に対するスナップショットを確認できます:
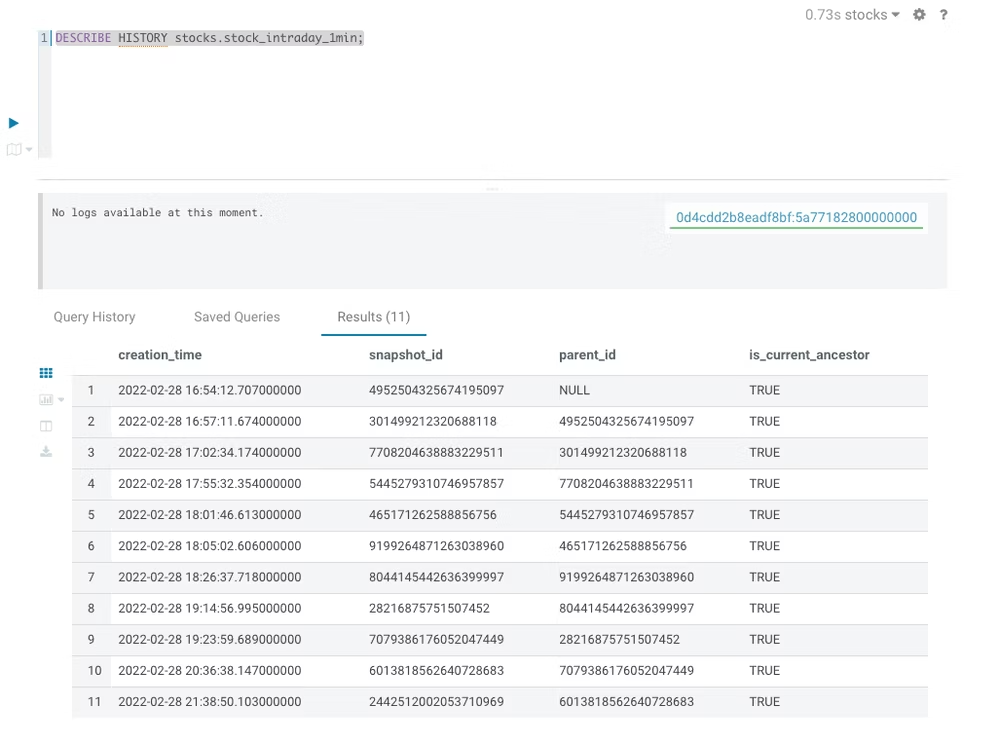
次に、以下のクエリを使用して、最後のスナップショットの前に持っていたティッカーをクエリします。snapshot_idを、最初のクエリで得た値に変更してください:
SELECT count(*), ticker FROM stocks.stock_intraday_1min FOR SYSTEM_VERSION AS OF <snapshotid> GROUP BY ticker;
今度はSnapshot_id抜きで試してみます:
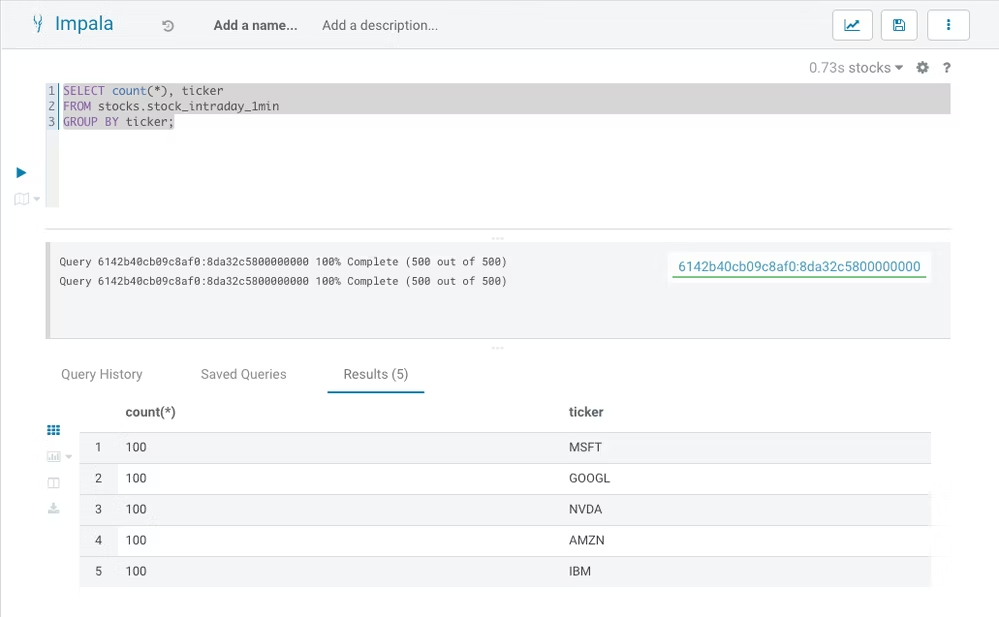
これでNVDAは最新のSnapshotに反映されていることを確認。
まとめ
今日はわずか数回のクリックで、データ取り込みおよび処理パイプラインを作成しました。
これがCloudera Data Platformのパワーです。パラメータのみを使用して簡単にデプロイできるエンドツーエンドのユースケースです。
今後Cloudera Machine Learningを使用して更に拡張することもできます。このブログには、機械学習のチュートリアル情報があります。
最後に、Cloudera Data Platform Public Cloud版にすでに統合されているApache Icebergのいくつか機能を使ってみました。