
この記事は、2026/1/27に公開された「Openness in the Age of AI」の翻訳です。
AI 革命が 1 つの普遍的なデータ管理の真理をもたらしたとすれば、それはデータ資産全体にわたるオープン性と相互運用性が求められるということです。結局のところ、AI が優れている点は、実際にアクセスできるデータによってのみ決まります。
企業はもはや切り離されたレガシー技術に投資する意欲はありません。サイロのコストはかつてインフラストラクチャだけで測定されていましたが、価値実現までの時間の損失と大規模な AI 実行の不可能性で測定すると、今では飛躍的に高くなります。このような状況を踏まえると、企業はデータアーキテクチャを見直さずにはいられません。
Cloudera では、オープン性を 3 層のデータ管理アーキテクチャとして定義しています(図 1を参照)。
オープンコンピューティング:データがどこに保存されているかに関係なく、任意のエンジンを使用できる機能
オープンカタログ:異なるデータアクセス層間でスワップインとスワップアウトや相互運用が可能で、表示エンジンに関係なくスキーマとガバナンスの整合性を確保する機能
オープンデータ:データ資産をどこにあっても移動してアクセスできること
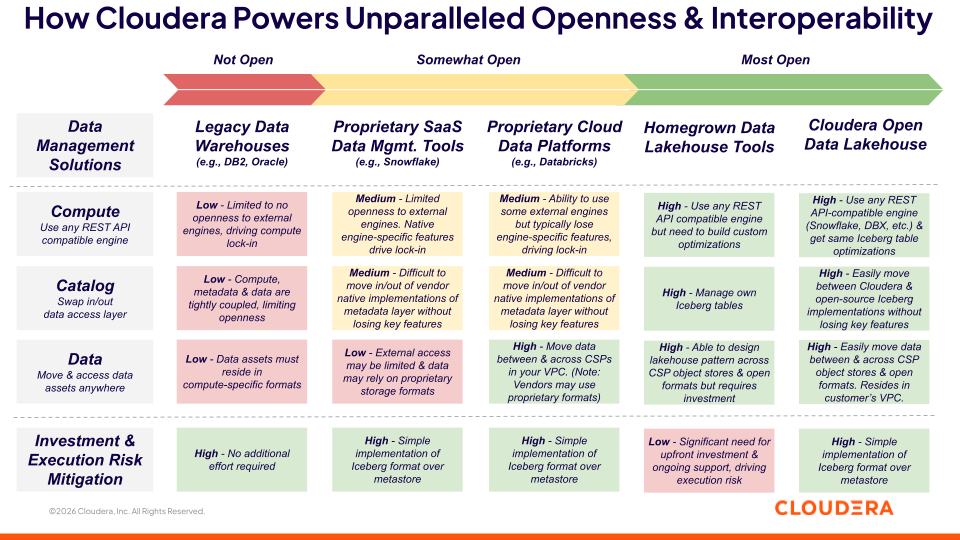
もっと広い意味で言えば、オープン性こそが Cloudera の中核です。
Apache Iceberg の初期提唱者:Cloudera は 2021 年からパブリッククラウドのレイクハウスで Iceberg のサポートを開始しました。他のベンダーもすぐに追随しました。これは、Iceberg がオープンテーブル形式の勝者であることを事実上認めたことになります。2024 年、Databricks は、オープンガバナンスと洗練された機能を評価して Tabular を買収しました。2025 年、Snowflake と Amazon Web Services(AWS)の両社は、Iceberg のサポートと機能の拡大に投資しました。
オープンソースの基盤とエコシステム:2008 年の設立以来、オープンソースコミュニティに深く関わっている Cloudera は、オープンソースのデータレイクテクノロジーを商業化した最初の企業であり、50 以上のオープンソースプロジェクトに貢献し、サポートを続けています。Cloudera のオープンソース基盤は、独自のオーバーレイによって顧客をロックインするベンダーと比べてはるかに簡単に、顧客が Cloudera ディストリビューションをオプトインまたはオプトアウトできるようにすることで、選択の自由を提供します。Cloudera の顧客は、縛りがないにもかかわらず、自ら使い続けることを選択しているのです。
データ管理スタック全体の相互運用性:オープンなコンピューティング、カタログ、データを提供することで、データ管理スタックの各レベルでの相互運用性が確保され、顧客はゼロから構築することなく AI 時代に真に勝利することができます。さらに、Cloudera は、どのコンピュートエンジンでも利用でき、データを任意のクラウドサービスプロバイダー(CSP)に配置する柔軟性を提供します。また、データの所在や使用するコンピューティングエンジンに関わらず、すべての機能に完全にアクセスできます。逆に、一部のベンダーは、スタックのすべてのレイヤーが同じプラットフォームで実行されているかどうかに基づいて機能へのアクセスを制限します。データを所有し、データをコントロールし、データを活用する。それが Cloudera の約束です。
AI 時代におけるオープン性の重要性についてより深く知りたい方は、当社のブログ「今存在する未来:AI 搭載のデータレイクハウス」をご覧ください。
