
この記事は、2025/11/13に公開された「A 5-Step Framework To Streamline Your Post-Merger Data Strategy」の翻訳です。
合併や買収(M&A)などのインオーガニック成長戦略は、戦略的な成長手段として機能し、企業は収益とコストの相乗効果を実現したり、長期的な競争上の優位性をもたらす新機能を迅速に獲得したりできます。たとえば現代では、大手企業が AI 変革の取り組みを加速し、競争上の優位性を獲得するために、小規模で革新的な AI スタートアップ企業を買収するケースが見られます。
テクノロジーの統合は、M&A による価値の獲得において重要な役割を果たします。Deloitte の調査では、IT は統合によるメリットを決定づける重要な要因であり、すべての相乗効果の50%以上を占めると主張しています。しかし、データサイロの増加とテクノロジーアーキテクチャや環境の多様化により、企業は合併後、テクノロジー統合のメリットを実現する上で、データに関するいくつかの課題に直面します。
この記事では、これらの課題に対処し、M&A 環境における価値獲得を加速するための5段階のフレームワークを紹介します。このフレームワークにより、Cloudera を使用した合併後のデータ戦略で、テクノロジー統合プロセスを効率化するために必要な機能を確実に利用できるようになります。
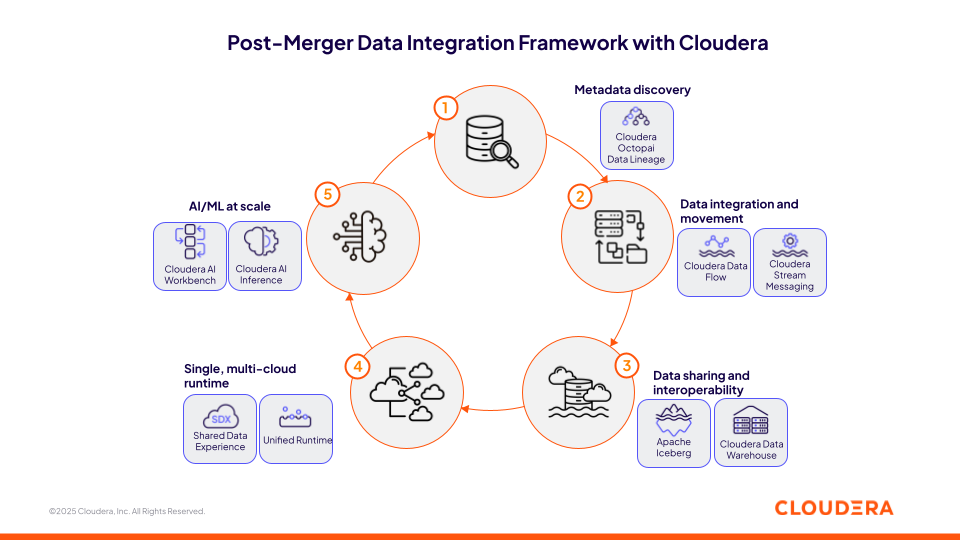
図1:Cloudera を使用した合併後のデータ統合フレームワーク
1. Cloudera Octopai Data Lineage で M&A 後の統合を加速する
合併後の統合の開始時には、断片化されたソースや文書化されていないソースにより、重要な分析とコンプライアンスに関する取り組みが遅れるため、データ検出フェーズがボトルネックになることがよくあります。Cloudera Octopai Data Lineage は、複雑なハイブリッド環境およびマルチクラウド環境におけるデータ検出、エンドツーエンドのリネージ、カタログ化を加速する AI 搭載の自動メタデータ管理ソリューションを提供することで、この課題に対処します。
Cloudera Octopai Data Lineage は、データフローを効果的にマッピングし、メタデータのギャップを埋めることで、完全な可視性を実現するために起源と変換を追跡する多次元的なリネージを提供します。Cloudera Octopai Data Lineage は、60以上のネイティブ統合と非ネイティブシステム用のユニバーサルコネクタを備えており、取得したデータエステートのオンボーディングを効率化することで、データの透明性、品質、信頼を向上させます。
たとえば、銀行の合併シナリオでこの機能を使用すると、リスク関連のデータセットを迅速に識別してタグ付けすることができ、BCBS 239 などの規制基準への準拠が保証されると同時に、大規模な手動監査や介入の必要性が最小限に抑えられます。
2. Cloudera データ・イン・モーションで異なるデータソースを統合する
多様なデータソースを統合し、複雑なカスタム ETL パイプラインを排除することは、合併後の重要な課題です。Cloudera は、Cloudera Data Flow(Apache NiFi 搭載)と Cloudera Streaming(Apache Kafka および Apache Flink 搭載)を通じて、バッチおよびリアルタイムのデータの取り込み、処理、配信を支える強力な機能を提供します。
450 を超えるコネクタを備えた Cloudera Data Flow は、オンプレミス、クラウド、エッジなど、ドラッグアンドドロップで操作でき、さまざまな異種データソースからデータを取り込めるビジュアルインターフェースを提供します。また、Cloudera Streaming は、2つのエンティティ間のソースシステムと消費システムを分離するメッセージングバスアーキテクチャを提供し、アーキテクチャの複雑さとコストの増加を招くポイントツーポイントの統合を排除します。
合併後の統合において、これらの機能は組織間のデータ移動を大幅に加速・簡素化します。たとえば、Cloudera Data Flow を使用すると、買収した会社の従来のソースシステムにあるオンプレミスのデータを親会社のクラウドネイティブなデータウェアハウスに迅速に統合し、意思決定を迅速化できます。
3. Apache Iceberg を使用して Cloudera オープンデータレイクハウス上に安全なデータ共有レイヤーを構築する
合併する組織間でのデータ共有は、意思決定を統一し、インサイトを得る上で不可欠ですが、多様な探索的データ分析やビジネスインテリジェンステクノロジー、異なるシステムで使用されるさまざまなデータセキュリティモデルが原因で、このプロセスが複雑になる可能性があります。
Cloudera のオープンデータレイクハウスアプローチでは、Apache Iceberg、Cloudera Iceberg REST Catalog、および Cloudera Shared Data Experience(SDX)を組み合わせて一元的なデータ共有レイヤーを開発できます。このレイヤーは、さまざまな分析エンジン(エンジンで Iceberg REST Catalog が有効になっている Snowflake、Databricks、AWS EMR、AWS Athena、Salesforce Data Cloud など)と互換性があり、新たに統合されたデータサイエンスチームを含むさまざまなユーザーのアクセスを管理するための、きめ細かなセキュリティとガバナンスモデルを提供します。
たとえば、医薬品製造に従事する2つの医療機関は、Cloudera を活用して規制要件に準拠しつつ、合併する組織のデータ資産を統合する GxP 準拠のデータレイクハウスを構築できます。
4. 単一のマルチクラウド環境で環境横断的な取り組みを標準化する
合併される2社で分析アクティビティに使用される環境が異なると、データ・インジェスチョンや標準化などの共通タスクで使用するデータエンジニアリングパイプラインが複数になるなど、データライフサイクル全体で操作が重複することにつながります。
Cloudera は、さまざまなプライベートクラウド環境やパブリッククラウド環境にわたって共通のランタイム上でデータと AI 操作を標準化できるようにします。この機能は、環境全体で基盤として使用されるコンテナ化されたインフラストラクチャモデル、一貫したユーザー認証・承認メカニズム(Cloudera SDX)、およびさまざまな展開環境とリージョンにわたるクラスターを管理するための一元化された管理パネルとして機能する Cloudera Manager から派生しています。
合併後の状況において、この標準化はまさに革命です。2社がデータライフサイクルでの操作を単一のランタイムに一元化できるため、冗長なツールがなくなり、データ、分析情報、AI モデルの共有が容易になります。これにより、データ運用や AI/ML モデル開発にかかる技術コストや人件費の削減、実務担当者の生産性の向上、複数のツールの統合、データサイロの削減が実現します。
5. Cloudera AI で AI イニシアチブをあらゆる場所へ拡大する
買収または合併後の当面の課題は、変化する容量需要を管理しながら、新たに買収した革新的なスタートアップ企業のさまざまなツール、モデル、データサイエンティストを統合することです。Cloudera AI Workbench と AI Inference は、以下を実現することで、オンプレミスまたはクラウドで AI イニシアチブを拡張できるようにします。
特徴量エンジニアリング、モデルトレーニング、実験追跡、モデル展開のためのコンテナベースのエンドツーエンドソリューションを提供する
データサイエンティストが異なるチーム間で共同作業できるよう、AI モデルの共有を促進する
Cloudera パートナーのハードウェアおよびソフトウェアアクセラレーションサービスを活用し、データエンジニアリングのパフォーマンスを20倍に、AI推論性能を最大6倍に向上させることで、データサイエンスのライフサイクル全体を高速化する
合併企業は Cloudera を利用することで、AI/ML モデルの提供などの永続的で計算集約型のワークロードをオンプレミス環境に移行し、コストを大幅に削減できます。また、新しい複合 AI アプリケーションの市場投入までの時間を短縮できることも重要です。これにより、組織は M&A で当初目指していた「競争優位性」を迅速に実現することができます。
合併・買収後の統合を成功させるための次のステップ
Cloudera を利用すれば、2つの組織間の合併後のデータ資産と分析機能の統合を加速できます。弊社プラットフォームは、データライフサイクル全体にわたる拡張性、インフラストラクチャに依存しない展開モデル、Cloudera のサービスと Apache Iceberg 上のデータレイクハウスとの相互運用性を提供します。この組み合わせにより、AI/ML イニシアチブとデータ操作を標準化し、Cloudera のサービスとそうでないサービスの両方で使用できるデータ共有モデルを提供するための、アーキテクチャの設計図が提供されます。
デモや製品ツアーをご希望の方は、弊社チームまでご連絡ください。
