Apache Druid
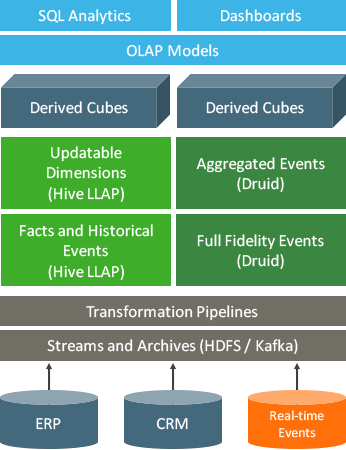
Druid は、ビジネスインテリジェンス (OLAP) のイベントデータのクエリのために設計された、オープンソース分析データストアです。Druid によって、低レイテンシ (リアルタイム) でデータ取り込み、柔軟なデータ検索、高速なデータ集約が可能になります。
Druid の動作の仕組み
Druid が高速な理由は、データを典型的な OLAP クエリパターンに適合するよう、インデックスを強化したカラムナフォーマットに変換している点にあります。Druidでは、HDP に含まれる Druid と Hive のコネクタを使用する Hive SQL、またはネイティブな REST API 経由でクエリが発行されます。

Druid の機能
| Feature | Description |
|---|---|
| Sub-Second Queries | Druid delivers sub-second queries, even when you have terabytes of data and dozens of dimensions. |
| Real-Time Data Ingestion | Druid makes real-time a reality. Query data seconds after it arrives. Native integration with Apache Kafka makes it simple to enable real-time analytics. |
| Integrated with Apache Hive | Build OLAP cubes and run sub-second SQL queries using any Hive-compatible tool. |
| Apache Ambari Integration | Apache Ambari makes deploying, configuring and monitoring Druid a breeze.. |
Druid にフォーカス
Cloudera は、時系列データとリアルタイムデータをシームレスに統合した、高速で拡張性に優れた分析の実現にフォーカスしています。
- リアルタイム分析:Druid / Hive コネクタで、SQL を使った OLAP キューブを作成したり、既存の Druid キューブを利用できるようになります。あるいは、Hive の強力な SQL サポートによって、Druid のデータを詳細に分析することも可能です。
- 管理:Apache Ambari によって、Druid クラスタの容易な導入、設定、監視、管理が可能になります。
- セキュリティ:Druid が Kerberos およびセキュアな Hadoop を完全にサポートできるようになり、また Apache Ambari を使って、これまで決して容易ではなかった Durid クラスタのセキュリティ管理も可能になりました。