Apache Zeppelin
インタラクティブなデータ分析を可能にする、完全にオープンな Web ベースのノートブック
Apache Zeppelinは、データの取り込み、データの探索、可視化、共有、およびコラボレーション機能をHadoopとSparkにもたらす、新しい多目的なWebベースのノートブックです。

Zeppelin の提供機能
データエンジニア、データアナリストやデータサイエンストは、インタラクティブなブラウザベースのノートブックを使って、データコードの作成、オーガナイズ、そして実行や共有を行い、コマンドラインを使用したり、クラスタの詳細を理解する必要なしに、実行結果を可視化することができます。これらのユーザーは、ノートブックを使用することで、長いワークフローの実行だけでなく、インタラクティブな操作も可能になります。Spark では、さまざまなノートブックが利用できます。iPython は、依然として完成度の高い選択肢であり、データサイエンスノートブックの優れた例です。Ambari のスタック定義を提供する Hortonworks Gallery を使用することで、Hadoop クラスタに iPython を素早く設定することができます。
間もなく新しく登場する Web ベースのノートブック Apache Zepplinは、データの探索、可視化、共有、コラボレーション機能を Spark に提供します。既にPythonに対応していますが、Scala や Hive、SparkSQL、shell や markdown など、サポート対象のプログラミング言語も増えています。
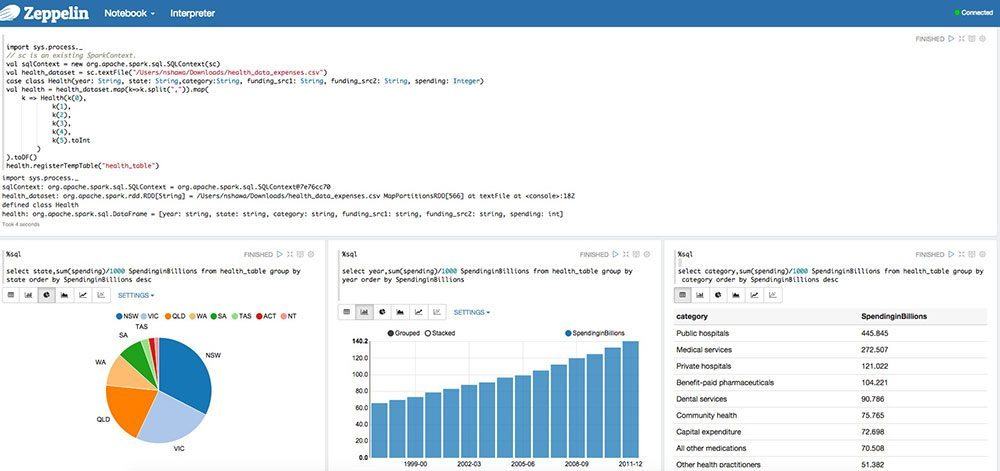
さまざな言語が、Zeppelin 言語インタプリタ経由でサポートされています。
データディスカバリ、探索、レポーティングおよび可視化機能は、データサイエンスワークフローの重要なコンポーネントです。Zeppelinでは、Spark と Hive をすぐに利用できる「Modern Data Science Studio」を提供しています。実際にZeppelin は、複数の言語バックエンドをサポートして、拡大を続けるデータソースのエコシステムを支えています。Zeppelin のノートブックは、データサイエンティストにインタラクティブなスニペットエクスペリエンスを提供します。Zeppelin ノートブックのコレクションについては、Hortonworks Galleryでご確認いただけます.
また、ノートブック使用後に共有したいインサイトがあれば、レポートを作成して容易に印刷あるいは送信することもできます。
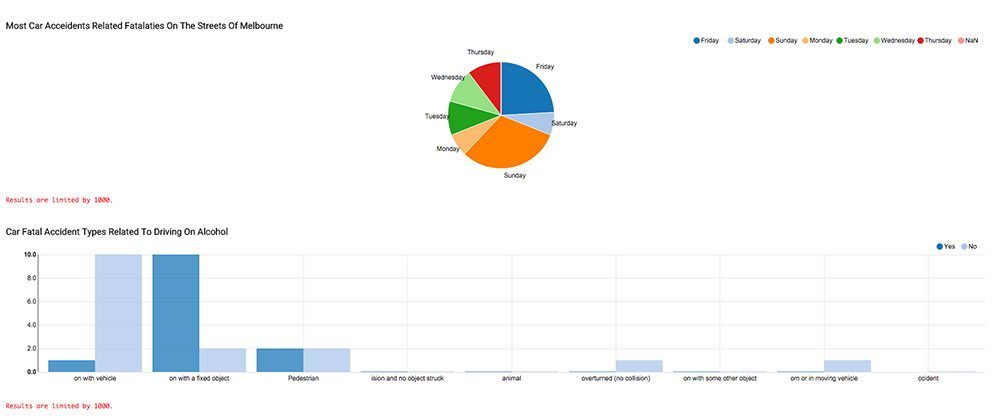
Clouderaでは、Spark と Hadoop が最高の組み合わせだと考えています。また、Zepplin は、データサイエンスソリューションを加速するための重要なコンポーネントです。
Web ノートブックの最近の進展
ノートブックにおいても、依然としてデータの処理プロセスは課題として残っています。データサイエンティストは、しばしば、機能エンジニアリングやアルゴリズムの選択、チューニング、結果の共有、業務への移行などで苦労することがあります。
Cloudera は、コミュニティにおいてZepplin ノートブックの改善にあたっています。Clouderaは、Zeppelin に Hive インタプリタを追加したり、エディタを安定させるといった改善に取り組んでいます。Clouderaでは、Zeppelin への関与を深め、セキュリティやサマリ統計、コンテキストセンシティブなヘルプ機能など、データ開発エクスペリエンの向上にも寄与しています。
