Fast Forward Labs 調査レポートが、サブスクリプション不要でご利用頂けるようになりました
今後、全ての新しいレポートは一般に公開され、無料でダウンロードできるようになります。さらに、過去の古いレポートのアップデートバージョンにもアクセスできるようにする予定です。利用可能な無料の調査レポートを頻繁にチェックしてみてください。
無料の調査レポート
誰でも無料でアクセスできる、最新の調査レポートとプロトタイプを確認する。
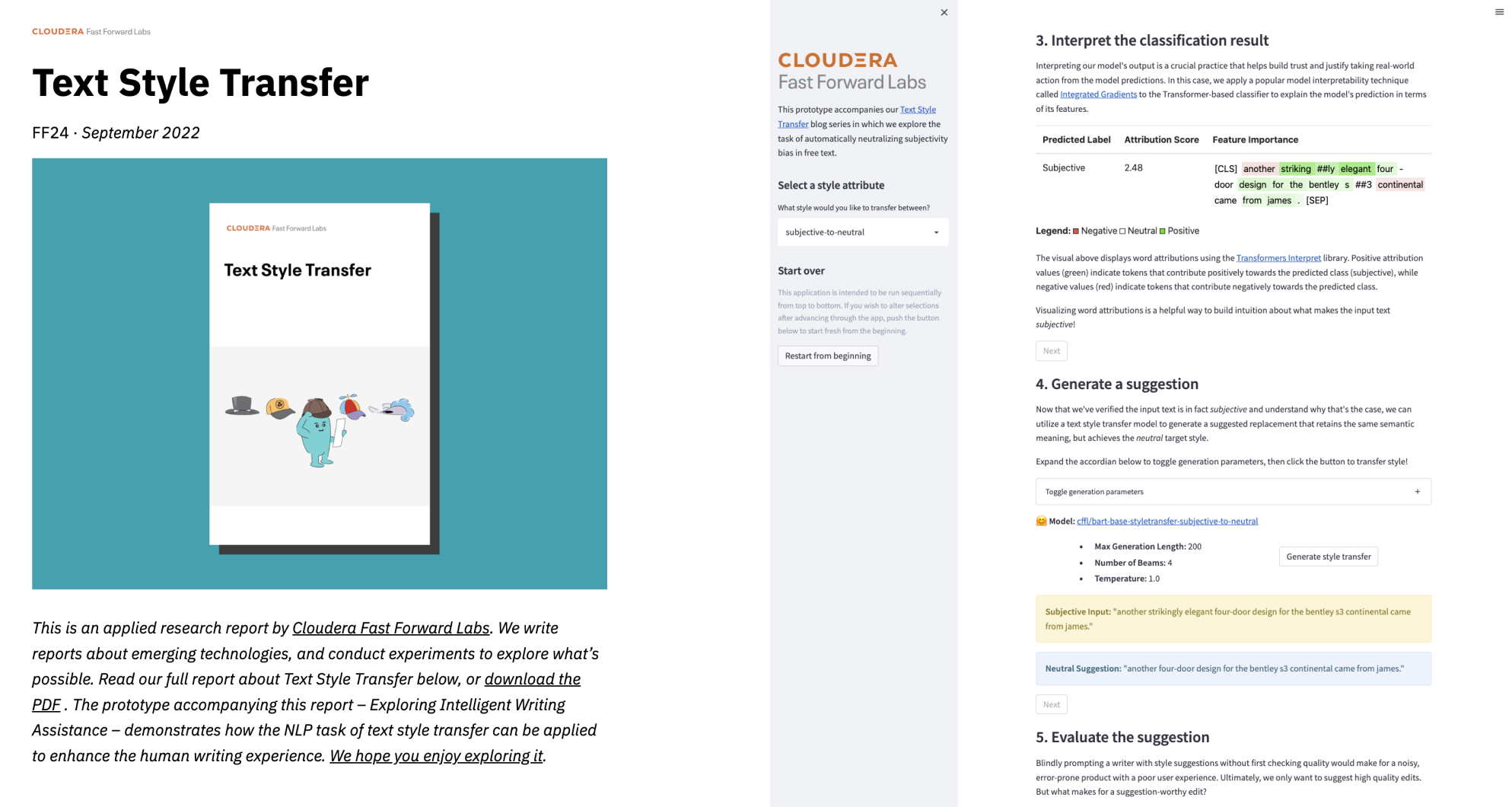
テキストスタイルの転送
テキストスタイル転送 (TST) の NLP タスクの目的は、コンテンツを保持しながらテキストのスタイル属性を自動的に制御することです。これは NLP をよりユーザー中心にするための重要な考慮事項です。このレポートでは、適用されたユースケースを通じて、フリーテキストの主観性バイアスを排除した、テキストスタイルの転送について説明します。その過程で、HuggingFace Transformers を活用したシーケンス間モデリングアプローチについても説明し、モデルのパフォーマンスを定量化するための一連のリファレンスフリーのカスタム評価メトリクスを提示します。最後に、弊社のプロトタイプ「Exploring Intelligent Writing Assistance」の中心にある倫理に関する解説をご紹介します。
ラベル付きデータなしでコンセプトドリフトを推定する
概念ドリフトとは、対象となるドメインの統計的特性が時間の経過とともに変化し、モデルの性能が低下することです。ドリフトの検出は、対象となるパフォーマンス指標を監視し、その指標がある指定された閾値を下回ったときに再トレーニングパイプラインをトリガーすることで実現されます。しかし、このアプローチは、予測時に十分な量のラベル付きデータが得られることを前提としていますが、多くの生産システムでは非現実的な制約となっています。本レポートでは、ラベル付きデータに容易にアクセスできない場合に、コンセプトドリフトに対処するための様々なアプローチを検討しています。





自動質問応答システム
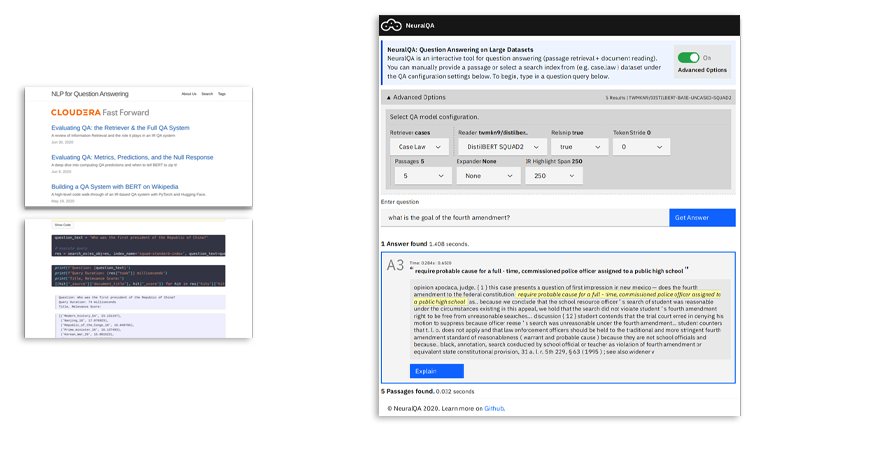
質問応答機能は、自然言語を使ってデータから情報を引き出すユーザーフレンドリーな機能です。最近の自然言語処理の進歩によって、非構造化テキストデータを使う質問応答機能が急速な発展を遂げています。このブログシリーズでは、包括的な質問応答システムを構築する上での概要を技術的、実践的に説明しています。

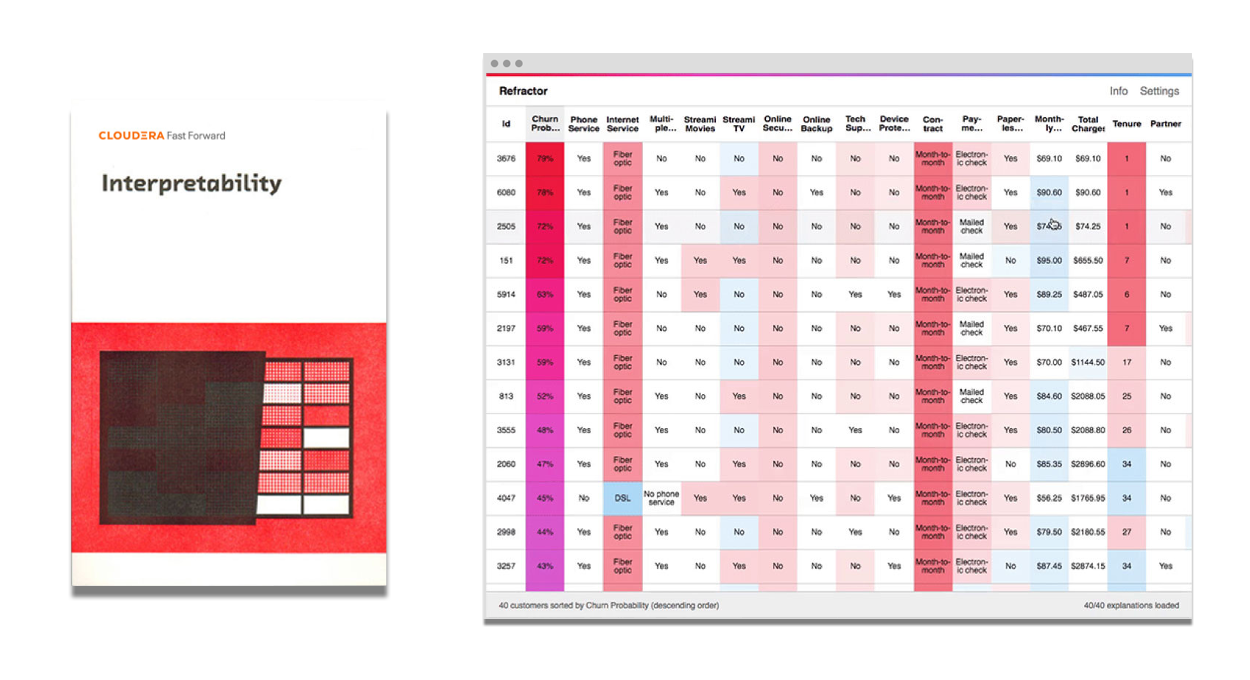
説明可能性:2020年版
説明可能性、つまりシステムが決定を下す理由と方法を説明する能力は、モデルの改善や規制対応、優れた製品の構築などに役立ちます。ディープラーニングのようなブラックボックスな技術は、説明可能性を犠牲にして画期的な機能を提供してきました。最近アップデートされた本レポートでは、SHAP のような技術を含め、機能や正確さを損なうことなく、説明可能性を備えたモデルを構築する方法について説明しています。
ニューラル言語処理のための転移学習
ディープラーニングを使用した自然言語処理 (NLP) テクノロジーによって、言葉の翻訳や質問への回答、人間に近い文書の作成などが可能になりますが、このようなディープラーニング技術には、大規模でコストの高いラベル付きデータセット、高価なインフラストラクチャー、希少な専門知識が必要です。転移学習は、モデルの言語理解を再利用して適応させることで、このような制約を取り除き、どのような NLP アプリケーションにも適合します。本レポートでは、転移学習を使って、最小限のリソースで高性能な NLP システムを構築する方法をご紹介します。

セマンティックレコメンデーション
インターネットにより、私たちが読むもの、見るもの、そして買うものの選択肢が爆発的に増えました。このため、特定の人の興味を引くアイテムを見つけるレコメンデーションアルゴリズムがこれまで以上に重要になっています。本レポートでは、アイテムとユーザーのセマンティックコンテンツを活用し、複数の業界にわたってより豊富なレコメンデーションを提供するレコメンデーションシステムについて説明します。

要約
このレポートでは、文書の要約を自動的に出力できる機能である抽出型要約の手法について探ります。何千もの製品レビューから要点を導き出したり、長文のニュース記事から最も重要な内容を抽出したり、顧客の経歴を自動的に集めてその人物像を割り出したり、この手法を活用できる分野は実にさまざまです。

確率論的手法によるリアルタイムストリーム
カムと歯車で構築されたアナログコンピューターの時代から今日に至るまで、処理すべきデータフローと重要な演算を中心にシステムが構築されてきました。設計の原理に変わりはありませんが、システムを構築するうえでの制約は常に進化しています。ここ5年間で、「ビッグデータ」、つまりコモディティインフラストラクチャーを使用して非常に大きなデータセットをまとめて分析する機能が台頭してきました。今は、リアルタイムのデータストリームを処理するために利用できるツール、方法、テクノロジーにおける進化のさなかにあります。

サブスクリプション限定レポート
古いレポートのアップデートバージョンは、今後無料で利用が可能となる予定です。是非、頻繁にご確認ください。

マルチタスク学習
本レポートでは、関連する複数のタスクを同時に学習させるアルゴリズムを可能にした、機械学習の新たなアプローチであるマルチタスク学習を特集しています。
{kind=link}

確率論的プログラミング
ここでは、より効果的な意思決定のための予測機能を提供するツールを容易に構築するための、確率論的プログラミングとベイジアン (Bayesian) インターフェースの使い方について説明しています。
{kind=link}

Fast Forward Labs のブログを読む
最新情報の入手
毎月提供されるニュースレターの配信登録を行い、人工知能応用技術の進展に関する最新情報、Cloudera のニュースやイベント情報を入手してください。