Apache Hadoop エコシステム
Hadoopは、企業がデータを格納、処理、および分析する方法を根本的に変えるオープンソースコンポーネントのエコシステムです。Hadoopを使用すると、従来のシステムとは異なり、業界標準のハードウェアで大規模に複数の種類の分析ワークロードを同じデータで同時に実行することができます。ClouderaのオープンソースプラットフォームであるCDHは、世界で最も人気のあるHadoopのディストリビューションと関連プロジェクトです(Cloudera Enterpriseのサブスクリプションによりサポートも利用できます)。
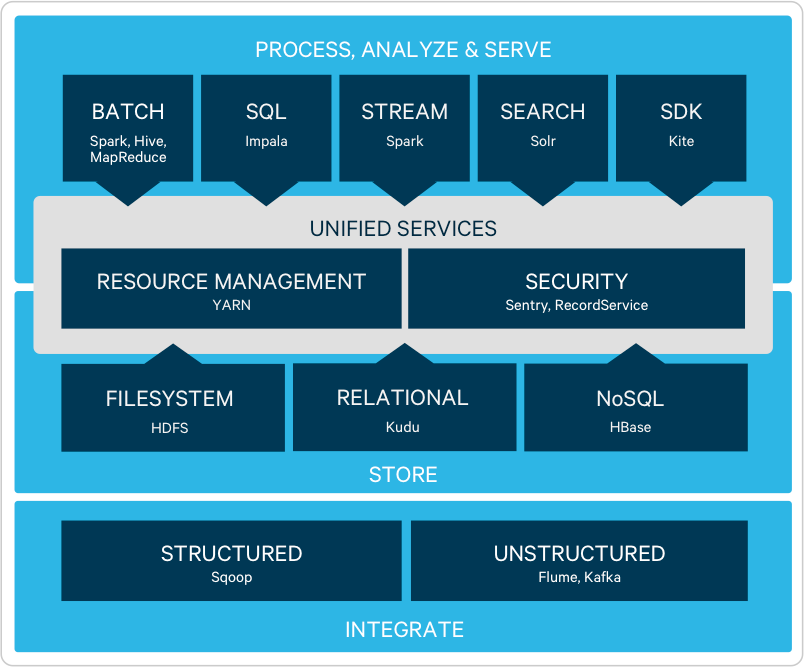
格納
(HDFSファイルシステムをベースとする)Hadoopの制限なく拡張可能で柔軟なアーキテクチャーでは、量と種類の制限なくデータの格納と分析の両方を業界標準ハードウェア上の単一オープンソースプラットフォームで実行できます。


データの処理
既存システムやアプリケーションと素早く連携し、データ一括ロード処理 (Apache Sqoop) やストリーミング処理 (Apache Flume、Apache Kafka) によって、Hadoopにデータを取り込んだり、抽出したりすることができます。
バッチ(MR2)処理または高速インメモリ(Apache Spark)処理用の複数のデータアクセスオプション(Apache Hive、Apache Pig)を使用して、より大規模で複雑なデータを変換することができます。Spark Streaming によって、クラスタに到着した時点でストリーミングデータを処理することができます。
ディスカバリ
アナリストは、Hadoop のためのデータウェアハウスである Apache Impala によって、すぐに完全なデータを利用することができます。Impalaにより、BI 品質の SQL 性能と機能に加え、すべての主要な BI ツールとの互換性を確保することができます。
HadoopとApache Solrを統合したCloudera Searchを使用すると、特にImpalaと組み合わせた場合にあらゆる量と形式のデータでパターンを発見する処理を高速化することができます。


モデリング
Hadoopによって、アナリストとデータサイエンティストは、パートナーのテクノロジーを組み合わせて使用したり、Apache Spark™ のようなオープンソースフレームワークを使用しながら、高度な統計モデルの作成や、繰り返しでの適用といった柔軟な対応が可能になります。
Serve
Hadoop用の分散データストアであるApache HBaseは、オンラインアプリケーションに必要な高速ランダム読み書き(「高速データ」)をサポートしています。

CDH:オープンソースとオープンスタンダードを土台に構築
世界で最も人気の高いHadoopディストリビューションであるCDHは、Clouderaの完全にオープンソースなプラットフォームです。CDHには、無制限のデータを格納、処理、発見、モデリング、および提供するための主要なHadoopエコシステムコンポーネントが全て含まれています。また、CDHは安定性と信頼性を実現する最高の企業水準を満たすように設計されています。
CDHは、長期的アーキテクチャー向けのオープンスタンダードに完全に準拠しています。また、Hadoop のオープンスタンダードの主要なキュレーターである Cloudera は、最終的にエコシステム全体で採用される新しいオープンソースソリューションをプラットフォーム(Apache Spark、Apache HBase、Apache Parquetなど)に取り込んだ実績を持っています。
