概要
あらゆる規模のデータパイプラインをセキュアに合理化して運用。
CDP Data Engineering は、エンタープライズデータエンジニアリングチーム向けに開発された唯一のクラウドネイティブサービスです。Apache Spark を基盤とする Data Engineering はあらゆるデータエンジニアリングツールを備えており、Apache Airflow によるオーケストレーション自動化、高度なパイプライン監視、視覚的なトラブルシューティングを実現し、包括的な管理ツールでエンタープライズ分析チームの ETL プロセスを合理化します。
Data Engineering は Cloudera Data Platform と完全に統合されており、SDX によるエンドツーエンドの可視性とセキュリティを実現できます。また、データウェアハウスや機械学習などの CDP サービスともシームレスに統合できます。ハイブリッドクラウドプラットフォーム上のあらゆる場所で、一貫性のある反復可能な自動データエンジニアリングワークフローを実現します。

ユースケース
あらゆる場所でデータパイプラインを自動化
ETL の可視性と統制を確保
全体にわたりデータの整合性を維持
あらゆる場所でデータパイプラインを自動化
質の高いデータセットを CDP Data Warehouse や CDP Machine Learning などの分析ツールへセキュアに提供。
Data Engineering は、機械学習やデータウェアハウスなど、分析チームへのデータパイプラインを合理化します。パイプラインのオーケストレーションと自動化により、キュレーションされた質の高いデータセットをセキュアかつ透過的にあらゆるところへ提供することで、価値実現までの時間を短縮します。

ETL の可視性と統制を確保
データライフサイクルを透過的かつ包括的に管理。
データパイプラインをエンタープライズ全体で大規模に運用しようとすると、データライフサイクルの管理とコストの抑制はますます複雑化します。
運用統制と可視化機能を兼ね備えた Data Engineering により、さまざまなビジネスユースケースにおいてキャパシティプランニング、パイプライン自動化、自動リネージキャプチャ、トラブルシューティングを実現できます。
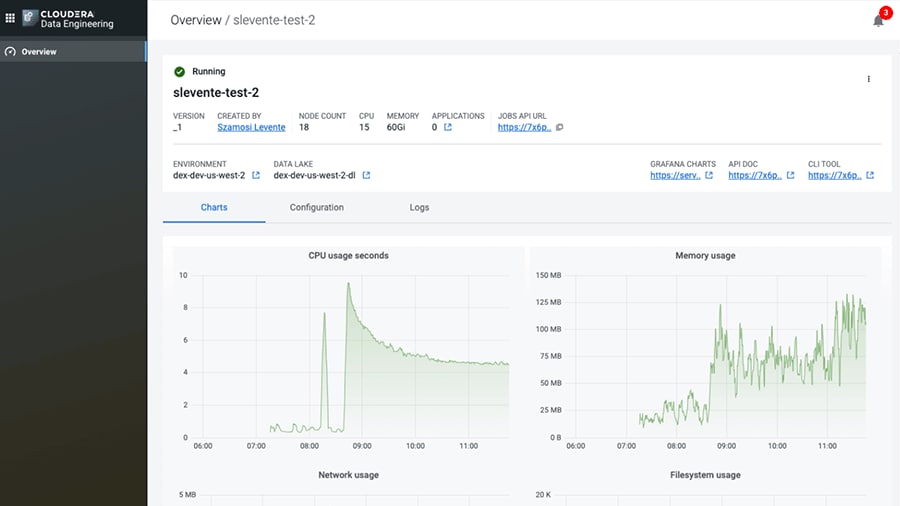
全体にわたりデータの整合性を維持
データパイプラインを完全に可視化してビジネスを保護。
データの量と複雑性が増大すると、分析ワークロードをビジネス全体に拡張しながら正確性と忠実性を維持することが困難になる場合もあります。
Data Engineering では、ネイティブなデータパイプライン監視とアラートにより、問題を早期に検出できます。また、視覚的なトラブルシューティングにより、問題がビジネスに影響を与える前に迅速に解決できます。
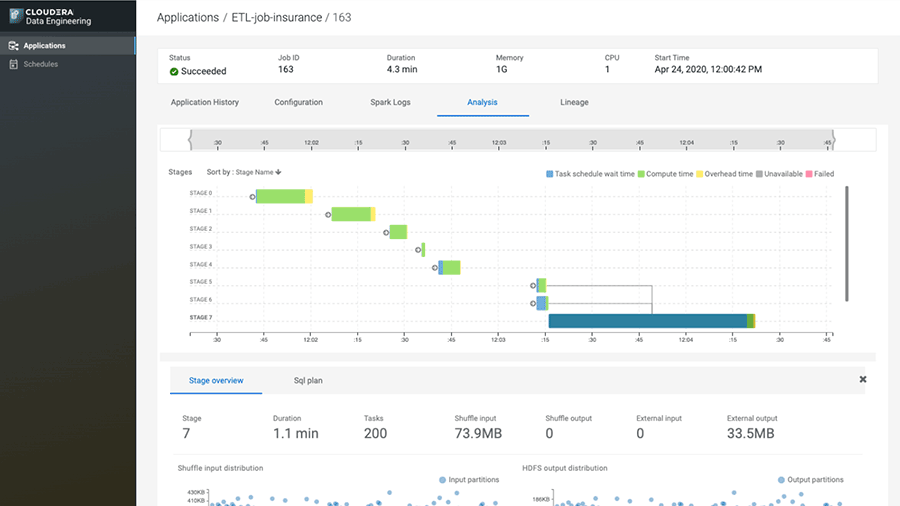
Apache Airflow と数百のオペレーターを使用して複雑なデータ変換ワークフローをオーケストレーションすることで、ミッションクリティカルな分析の要件を満たすことができます。
Data Engineering はコンテナ化されており、拡張性とポータビリティに優れ、分離されたワークロード環境とガードレールを使用します。オンデマンドの弾力的なコンピューティングによるセキュアなパイプライン管理を実現し、ビジネスの SLA をコスト効率良く満たすことができます。
Spark ジョブのすべての段階で CPU、メモリ、I/O などのパフォーマンスメトリクスを視覚化します。トラブルシューティングではパフォーマンスのボトルネックを特定し、大量のデータからわずかな異常を発見します。
CLI および REST API を介して豊富なジョブ管理インターフェースを利用し、CI や CD パイプラインなどの既存ワークフローやサードパーティー製ツールなどを簡単に自動化および統合できます。
Data Engineering は Kubernetes サービス上に Spark を完全統合し、アーティファクト管理、セキュリティ、リソーススケジューリングを自動化および合理化します。FIFO と GANG のスケジューリングには Apache Yunikorn を使用します。
プラットフォーム管理者は、一元化されたインターフェースからアクセスとセキュリティを管理し、新しいワークロードを迅速にプロビジョニングできます。また、キャパシティの監視やリソース使用率推移の視覚化も容易です。また、SDX ではライフサイクル全体におけるリネージ追跡ができるため、データがどこから来てどこへ行くかが分かります。
ご興味をお持ちであれば、詳しい内容をぜひご覧ください
Cloudera Data Platform の Data Engineering を体験